Elon Musk
What we want to show today is
- that Tesla is much more than an electric car company
- that we have deep AI activity
- in hardware
- on the inference level
- on the training level
I think we’re arguably the leaders in real world AI as it applies to the real world. Those of you who have seen the FSD Beta can appreciate the rate at which the Tesla neural net is learning to drive.
So, this is a particular application of AI, but I think there are more applications down the road that will make sense and we’ll talk about that later in the presentation.
We basically want to encourage anyone who is interested in solving real-world AI problems at either the hardware or the software level to consider joining Tesla.
Andrej Karpathy (lead in the vision team at Tesla Autopilot)
The Vision Component
So, we’re going to start off with the vision component.
In the vision component we’re trying to design a neural network that processes the raw information - which in our case is the eight cameras that are positioned around the vehicle and they send us images and we need to process that in real time - into what we call the vector space. This is a three-dimensional representation of everything you need for driving. So, this is the three-dimensional positions of lines, edges, curbs, traffic signs, traffic lights and cars (their positions, orientations, depth, velocities and so on).
So, here I’m showing a video of the raw inputs that come into the stack and then the neural network processes that into the vector space. You are seeing parts of that vector space rendered in the instrument cluster on the car.
The car can be thought of as an animal
[slide: biological visual cortex wiring]
Now, what I find kind of fascinating about this is that we are effectively building a synthetic animal from the ground up.
So, the car can be thought of as an animal. It moves around, it senses the environment and acts autonomously and intelligently and we are building all the components from scratch in-house.
So, we are building, of course, all of the mechanical components of the body, the nervous system, i.e. all the electrical components and for our purposes the brain of the Autopilot and specifically for this section [of the presentation] the synthetic visual cortex. Now, the biological visual cortex actually has quite intricate structure and a number of areas that organize the information flow of this brain. In particular, in our visual cortices the information, i.e. the light, hits the retina, it goes through the LGN all the way to the back of your visual cortex, goes through areas v1, v2, v4, and the IT [see “Inferior temporal gyrus”], the ventral and the dorsal streams [see “Two-streams hypothesis”] and the information is organized in a certain layout.
So, when we are designing the visual cortex of the car, we also want to design the neural network architecture of how the information flows in the system.
[slide: camera input]
So, the processing starts in the beginning when light hits our artificial retina and we are going to process this information with neural networks.
HydraNet
Now, I’m going to roughly organize this section chronologically.
So, starting off with some of the neural networks and what they looked like roughly four years ago when i joined the team and how they have developed over time. Roughly four years ago the car was mostly driving in a single lane going forward on the highway and so it had to keep lane and it had to keep distance away from the car in front of us. At that time all of processing was only on individual image level. So, a single image has to be analyzed by a neural net and make little pieces of the vector space process that into little pieces of the vector space. This processing took the following shape:
- We take a 1280 by 960 input and this is 12 bit integers streaming in at roughly 36 hertz
- [Neural Network Backbone] Now we’re going to process that with the neural network, so, instantiate a feature extractor backbone - in this case we use residual neural networks - so, we have a stem and a number of residual blocks connected in series
- Now the specific class of ResNets that we use are RegNets because RegNets offer a very nice design space for neural networks because they allow you to very nicely trade off latency and accuracy
-
Now these RegNets give us as an output a number of features at different resolutions in different scales.
In particular, on the very bottom of this feature hierarchy we have very high resolution information with very low channel counts. All the way at the top we have low resolution spatially, but high channel counts. So, on the bottom we have a lot of neurons that are really scrutinizing the details of the image and on the top we have neurons that can see most of the image and have a lot of that scene context.
-
[slide: Multi-Scale Feature Pyramid Fusion] We then like to process this with feature pyramid networks. In our case we would like to use BiFPNs. They get to multiple scales to talk to each other effectively and share a lot of information.
So, for example, if you’re a neuron all the way down in the network and you’re looking at a small patch and you’re not sure if this is a car or not, it definitely helps to know from the top layers that, hey, you are actually in the vanishing point of this highway. So, that helps you disambiguate that this is probably a car.
-
[slide: Detection Head] After a BiFPN and a feature fusion across scales we then go into task specific heads.
So, for example, if you are doing object detection, we have a one stage YOLO-like object detector. Here, where we initialize a raster and there’s a binary bit per position telling you whether or not there’s a car there and then, in addition to that, if there is [a car], here’s a bunch of other attributes you might be interested in. So, the x and y with height offset or any of the other attributes like what type of a car is this and so on. So, this is for the detection by itself.
-
Now very quickly we discovered that we don’t just want to detect cars, we want to do a large number of tasks. So, for example we want to do traffic light recognition and detection, a lane prediction and so on. So, very quickly we converged to this kind of architectural layout, where there’s a common shared backbone and then [the network] branches off into a number of heads. We call these therefore HydraNets and these are the heads of the Hydra.
This architectural layout has a number of benefits:
- Because of the feature sharing we can amortize the forward pass inference in the car at test time and so this is very efficient to run. Because, if we had to have a backbone for every single task, that would be a lot of backbones in the car.
- This decouples all of the tasks. So, we can individually work on every one task in isolation and for example, we can upgrade any of the data sets or change some of the architecture of the head and so on and you are not impacting any of the other tasks. So, we don’t have to revalidate all the other tasks which can be expensive
- Because there’s this bottleneck here [see slide: Multi-Task Learning HydraNets] in features, what we do fairly often is that we actually cache these features to disk and when we are doing these fine-tuning workflows we only fine-tune from the cached features up and only fine-tune the heads. So, most often in terms of our training workflows we will do an end-to-end training run once in a while, where we train everything jointly, then we cache the features at the multiscale feature level and then we fine-tune off of that for a while and then end-to-end training once again and so on.
[video with HydraNet predictions] So, here’s the kinds of predictions that we were obtaining I would say several years ago from one of these HydraNets. So, again, we are processing just [an] individual image and we’re making a large number of predictions about these images. So, for example, here you can see predictions of the stop signs, the stop lines, the lines, the edges, the cars, the traffic lights, the curbs here, whether or not the car is parked, all of the static objects like trash cans, cones and so on. Everything here is coming out of the net, in this case out of the HydraNet.
Smart Summon, Occupancy Tracker
So, that was all fine and great, but as we worked towards FSD we quickly found that this is not enough. So, where this first started to break was when we started to work on Smart Summon.
[video: curb detection for every camera] Here, I am showing some of the predictions of only the curb detection task and I’m showing it now for every one of the cameras. So, we’d like to wind our way around the parking lot to find the person who is summoning the car. Now the problem is that you can’t just directly drive on image space predictions. You actually need to cast them out and form some kind of a vector space around you.
[slide: Occupancy Tracker] So, we attempted to do this using C++ and developed what we called the Occupancy Tracker at the time. So, here we see that the curb detections from the images are being stitched up across camera boundaries and over time. Now there are two major problems with the setup:
- We very quickly discovered that tuning the Occupancy Tracker and all of its hyperparameters was extremely complicated. You don’t want to do this explicitly by hand in C++. You want this to be inside the neural network and train that end-to-end.
-
We very quickly discovered that the image space is not the correct output space. You don’t want to make predictions in image space. You really want to make it directly in the vector space.
So here’s a way of illustrating the issue [slide: Problem: Per-Camera Detection Then Fusion]. Here, I’m showing on the first row the predictions of our curbs and our lines in red and blue. They look great in the image, but, once you cast them out into the vector space, things start to look really terrible and we are not going to be able to drive on this. So, you see how the predictions are quite bad in vector space. The reason for this fundamentally is because you need to have an extremely accurate depth per pixel in order to actually do this projection. So, you can imagine just how high of a bar it is to predict that depth so accurately in every single pixel of the image. And also, if there’s any occluded area where you’d like to make predictions, you will not be able to because it’s not an image space concept in that case.
The other problem with this by the way is for object detection, if you are only making predictions per camera, then sometimes you will encounter cases like this where a single car actually spans five of the eight cameras. So, if you are making individual predictions, then no single camera sees all of the car and so obviously you’re not going to be able to do a very good job of predicting that whole car and it’s going to be incredibly difficult to fuse these measurements.
Multi-Cam Vector Space Predictions
So we have this intuition that what we’d like to do instead is we’d like to take all of the images and simultaneously feed them into a single neural net and directly output in vector space. Now this is very easily said, much more difficult to actually achieve.
But roughly we want to lay out a neural net in this way, where we process every single image with a backbone. And then we want to somehow fuse them and we want to re-represent the features from image space features to directly some kind of vector space features and then go into the decoding of the head.
Now, there are two problems with this.
Problem number one: how do you actually create the neural network components that do this transformation and you have to make it differentiable so that end-to-end training is possible.
And number two: if you want vector space predictions from your neural net you need vector specif based data sets. So just labeling images and so on is not going to get you there. You need vector space labels.
We’re going to talk a lot more about problem number two later in the talk. For now I want to focus on the neural network architectures. So, I’m going to deep dive into problem number one.
![]()
So, here’s the rough problem right. We’re trying to have this bird’s eye view prediction instead of image space predictions. So, for example let’s focus on a single pixel in the output space in yellow. And this pixel is trying to decide “Am I part of a curb or not?”, as an example. And now, where should the support for this kind of a prediction come from in the image space? Well, we know roughly how the cameras are positioned and their extrinsics and intrinsics. So, we can roughly project this point into the camera images. And you know the evidence for whether or not this is a curb may come from somewhere here in the images. The problem is that this projection is really hard to actually get correct because it is a function of the road surface. The road surface could be sloping up or sloping down or also there could be other data dependent issues. For example, there could be occlusion due to a car. So, if there’s a car occluding this viewport, this part of the image, then actually you may want to pay attention to a different part of the image, not the part where it projects. And so, because this is data dependent, it’s really hard to have a fixed transformation for this component.
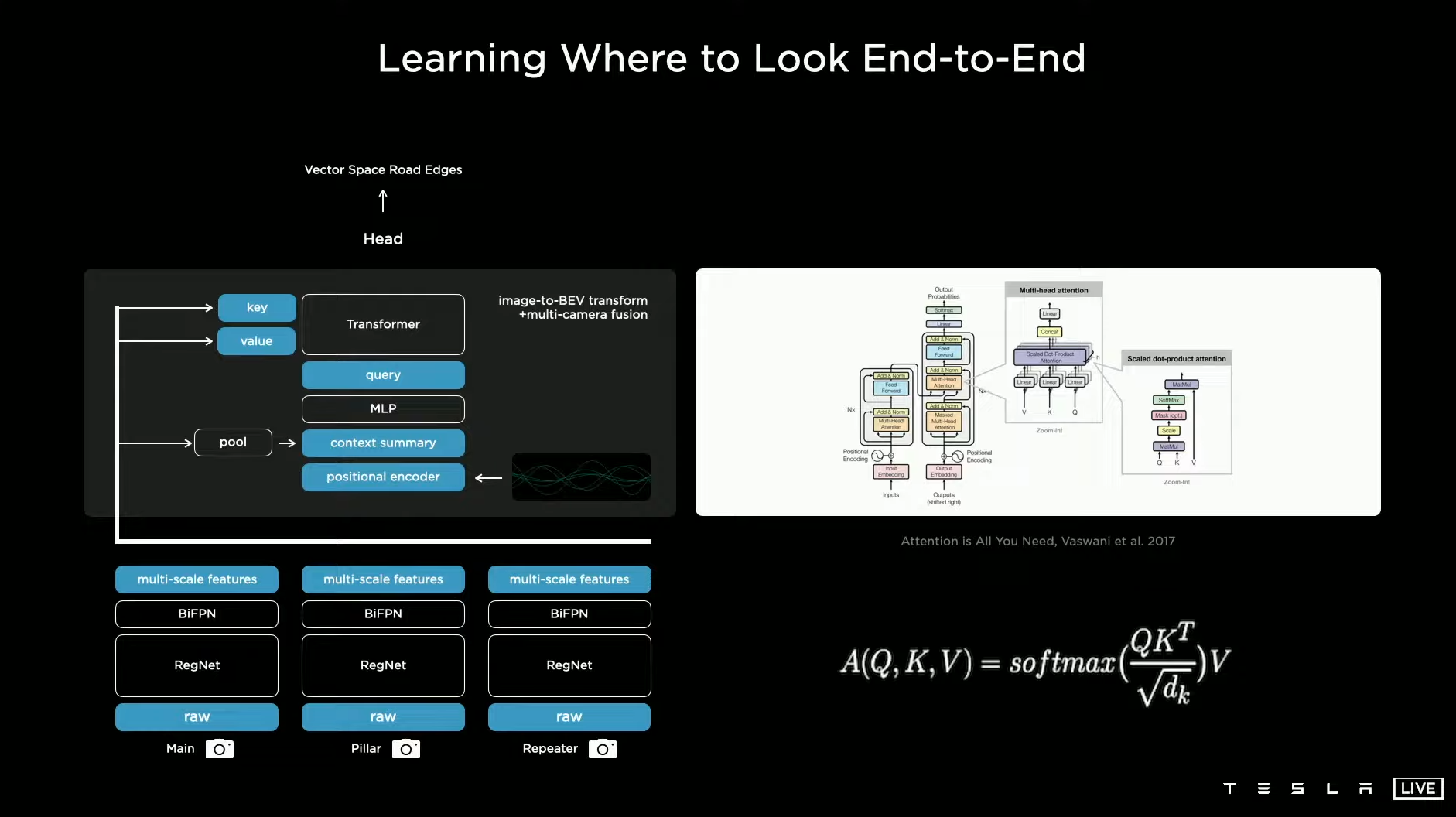
So, in order to solve this issue, we use a transformer to represent this space. And this transformer uses multi-headed self-attention and blocks (modules) of it. In this case actually we can get away with even a single block doing a lot of this work. And effectively what this does is, you initialize a raster of the size of the output space that you would like and you tile it with positional encodings with sines and cosines in the output space. And then, these get encoded with an MLP into a set of query vectors. And then, all of the images and their features also emit their own keys and values. And then, the queries, keys and values feed into the multi-headed self-attention. And so, effectively what’s happening is that every single image piece is broadcasting in its key what it is a part of. So, “Hey, I’m part of a pillar in roughly this location and I’m seeing this kind of stuff.”, and that’s in the key. And then, every query is something along the lines of “Hey, I’m a pixel in the output space at this position and I’m looking for features of this type.”. Then the keys and the queries interact multiplicatively and then the values get pooled accordingly. And so, this re-represents the space and we find this to be very effective for this transformation.
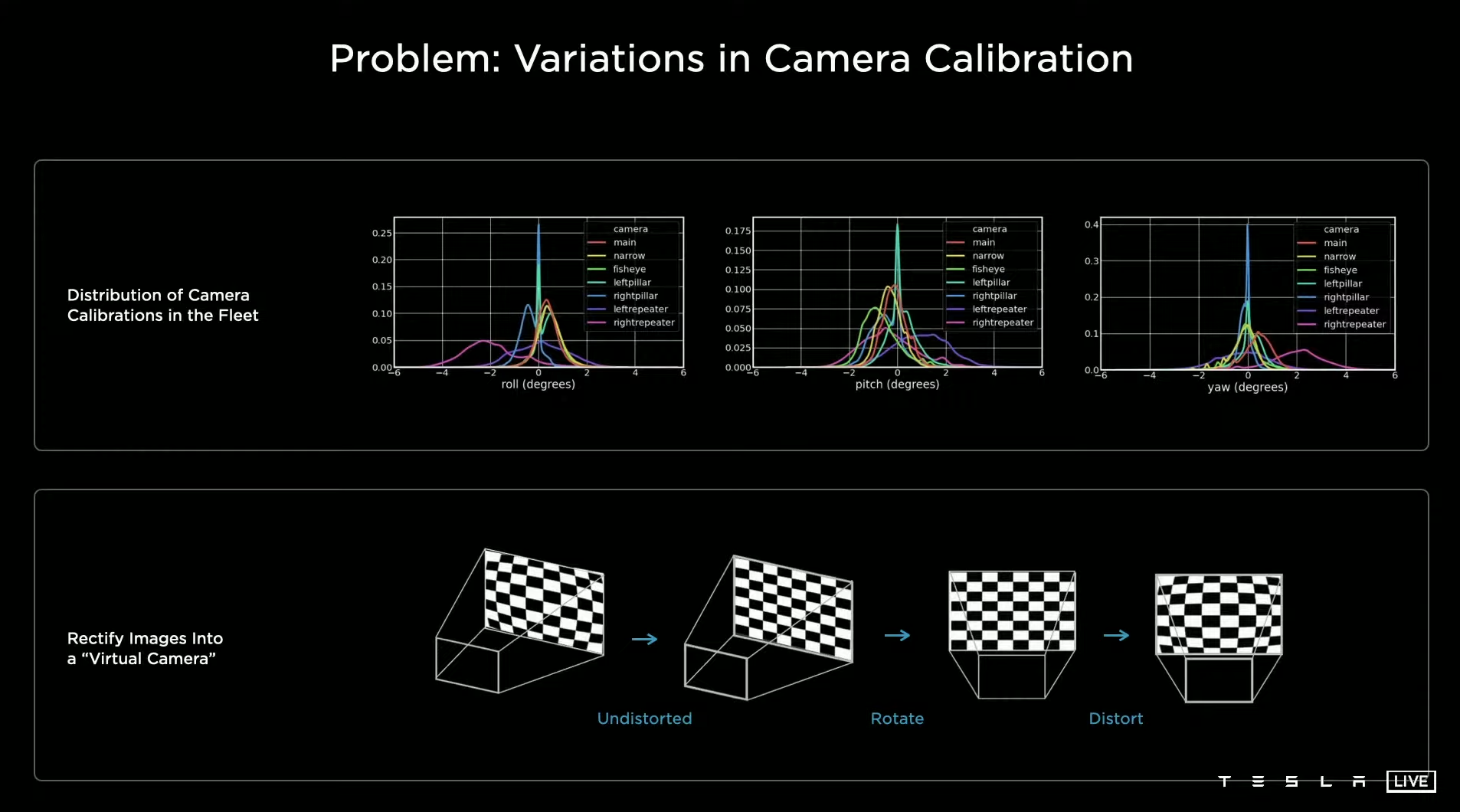
So, one more thing. You have to be careful with some of the details here, when you are trying to get this to work. So, in particular, all of our cars are slightly cockeyed in a slightly different way. And so, if you’re doing this transformation from image space to the output space, you really need to know what your camera calibration is and you need to feed that somehow into the neural net. And so you could definitely just like concatenate the camera calibrations of all of the images and somehow feed them in with an MLP, but actually we found that we can do much better by transforming all of the images into a synthetic virtual camera using a special rectification transform.

So, this is what that would look like. We insert a new layer right above the image rectification layer. It’s a function of camera calibration and it translates all of the images into a virtual common camera. So, if you were to average up a lot of repeater images, for example, which faced at the back you would without doing this you would get a kind of a blur. But after doing the rectification transformation you see that the back mirror gets really crisp. So, once you do this this improves the performance quite a bit.
Watch Youtube: t=3755
So, here are some of the results. So, on the left we are seeing what we had before and on the right we’re now seeing significantly improved predictions coming directly out of the neural net. This is a multi-camera network predicting directly in vector space. And you can see that it’s basically night and day. You can actually drive on this. And this took some time and some engineering and incredible work from the AI team to actually get this to work and deploy and make it efficient in the car.
Watch Youtube: t=3781
This also improved a lot of our object detection. So, for example, here in this video I’m showing single camera predictions in orange and multi-camera predictions in blue. And basically, if you can’t predict these cars, if you are only seeing a tiny sliver of a car, your detections are not going to be very good and their positions are not going to be good. But a multi-camera network does not have an issue.
Watch Youtube: t=3800
Here’s another video from a more nominal sort of situation. And we see that, as these cars in this tight space cross camera boundaries, there’s a lot of jank that enters into the predictions and basically the whole setup just doesn’t make sense, especially for very large vehicles like this one. And we can see that the multi-camera networks struggle significantly less with these kinds of predictions.

Okay, so, at this point we have multi-camera networks and they’re giving predictions directly in vector space. But we are still operating at every single instant in time completely independently. So very quickly we discovered that there’s a large number of predictions we want to make that actually require the video context and we need to somehow figure out how to feed this (video context) into the net. So, in particular, is this car parked or not? Is it moving? How fast is it moving? Is it still there, even though it’s temporarily occluded? Or, for example, if I’m trying to predict the road geometry ahead, it’s very helpful to know of the signs or the road markings that I saw 50 meters ago.
TODO: So, we tried to insert video modules into our neural network architecture and this is kind of one of the solutions that we’ve converged on. So we have the multi-scale features as we had them from before and what we are going to now insert is a feature queue module that is going to cache some of these features over time and then a video module that is going to fuse this information temporally and then we’re going to continue into the heads that do the decoding now i’m going to go into both of these blocks one by one also in addition notice here that we are also feeding in the kinematics this is basically the velocity and the acceleration that’s telling us about how the car is moving so not only are not only are we going to keep track of what we’re seeing from all the cameras but also how the car has traveled so here’s the feature queue and the rough layout of it we are basically concatenating these features um over time and the kinematics of how the car has moved and the positional encodings and that’s being concatenated encoded and stored in a feature queue and that’s going to be consumed by a video module now there’s a few details here again to get right so in particular with respect to the pop and push mechanisms and when do you push and how and especially when do you push basically so here’s a cartoon diagram illustrating some of the challenges here there’s going to be the ego cars coming from the bottom and coming up to this intersection here and then traffic is going to start crossing in front of us and it’s going to temporarily start occluding some of the cars ahead and then we’re going to be stuck at this intersection for a while and just waiting our turn this is something that happens all the time and is a cartoon representation of some of the challenges here so number one with respect to the feature queue and when we want to push into a queue obviously we’d like to have some kind of a time-based queue where for example we enter the features into the queue say every 27 milliseconds and so if a car gets temporarily occluded then the neural network now has the power to be able to look and reference the memory in time and and learn the association that hey even though this thing looks occluded right now there’s a record of it in my previous features and i can use this to still make a detection so that’s kind of like the more obvious one but the one that we also discovered is necessary in our case is for example suppose you’re trying to make predictions about the road surface and the road geometry ahead and you’re trying to predict that i’m in a turning lane and the lane next to us is going straight then it’s really necessary to know about the line markings and the signs and sometimes they occur a long time ago and so if you only have a time-based queue you may forget the features while you’re waiting at your red light so in addition to a time-based q we also have a space-based view so we push every time the car travels a certain fixed distance so some of these details actually can matter quite a bit and so in this case we have a time based key and a space base key to cache our features and that continues into the video module now for the video module we looked at a number of possibilities of how to fuse this information temporally so we looked at three-dimensional convolutions transformers axial transformers in an effort to try to make them more efficient recurrent neural networks over a large number of flavors but the one that we actually like quite a bit as well and i want to spend some time on is a spatial recurrent neural network video module and so what we’re doing here is because of the structure of the problem we’re driving on two-dimensional surfaces we can actually organize the hidden state into a two-dimensional lattice and then as the car is driving around we update only the parts that are near the car and where the car has visibility so as the car is driving around we are using the kinematics to integrate the position of the car in the hidden features grid and we are only updating the rnn at the points where where we have uh that are nearby us sort of so here’s an example of what that looks like here what i’m going to show you is the car driving around and we’re looking at the hidden state of this rnn and these are different channels in the hidden state so you can see that this is after optimization and training this neural net you can see that some of the channels are keeping track of different aspects of the road like for example the centers of the road the edges the lines the road surface and so on here’s another cool video of this so this is looking at the mean of the first 10 channels in the hidden state for different traversals of different intersections and all i want you to see basically is that there’s cool activity as the recurrent neural network is keeping track of what’s happening at any point in time and you can imagine that we’ve now given the power to the neural network to actually selectively read and write to this memory so for example if there’s a car right next to us and is occluding some parts of the road then now the network has a has the ability to not write to those locations but when the car goes away and we have a really good view then the recurring neural net can say okay we have very clear visibility we definitely want to write information about what’s in that part of space here’s a few predictions that show what this looks like so here we are making predictions about the road boundaries in red intersection areas in blue road centers and so on so we’re only showing a few of the predictions here just to keep the visualization clean um and yeah this is this is done by the spatial rnn and this is only showing a single clip a single traversal but you can imagine there could be multiple trips through here and basically number of cars a number of clips could be collaborating to build this map basically and effectively an hd map except it’s not in a space of explicit items it’s in a space of features of a recurrent neural network which is kind of cool i haven’t seen that before the video networks also improved our object detection quite a bit so in this example i want to show you a case where there are two cars over there and one car is going to drive by and occlude them briefly so look at what’s happening with the single frame and the video predictions as the cars pass in front of us yeah so that makes a lot of sense so a quick playthrough through what’s happening when both of them are in view the predictions are roughly equivalent and you are seeing multiple orange boxes because they’re coming from different cameras when they are occluded the single frame networks drop the detection but the video module remembers it and we can persist the cars and then when they are only partially occluded the single frame network is forced to make its best guess about what it’s seeing and it’s forced to make a prediction and it makes a really terrible prediction but the video module knows that there’s only a partial that you know it has the information and knows that this is not a very easily visible part right now and doesn’t actually take that into account we also saw significant improvements in our ability to estimate depth and of course especially velocity so here i’m showing a clip from our remove the radar push where we are seeing the radar depth and velocity in green and we were trying to match or even surpass of course the signal just from video networks alone and what you’re seeing here is in orange we are seeing a single frame performance and in blue we are seeing again video modules and so you see that the quality of depth is much higher and for velocity the orange signal of course you can’t get velocity out of a single frame network so we use uh we just differentiate depth to get that but the video module actually is basically right on top of the radar signal and so we found that this worked extremely well for us so here’s putting everything together this is what our architectural roughly looks like today so we have raw images feeding on the bottom they go through rectification layer to correct for camera calibration and put everything into a common uh virtual camera we pass them through regnets residual networks to process them into a number of features at different scales we fuse the multi-scale information with by fbn this goes through transformer module to re-represent it into the vector space in the output space this feeds into a feature queue in time or space that gets processed by a video module like the spatial rnn and then continues into the branching structure of the hydra net with trunks and heads for all the different tasks and so that’s the architecture roughly what it looks like today and on the right you are seeing some of its predictions uh sort of visualize both in a top-down vector space and also in images so definitely uh this architecture has definitely complexified from just a very simple image based single network about three or four years ago and continues to evolve um it’s definitely quite impressive now there’s still opportunities for improvements that the team is actively working on for example you’ll notice that our fusion of time and space is fairly late in neural network terms so maybe we can actually do earlier fusion of space or time and do for example cost volumes or optical flow-like networks on the bottom or for example our outputs are dense rasters and it’s actually pretty expensive to post-process some of these dense rasters in the car and of course we are under very strict latency requirements so this is not ideal we actually are looking into all kinds of ways of predicting just the sparse structure of the road maybe like you know point by point or in some other fashion that is that doesn’t require expensive post-processing but this basically is how you achieve a very nice vector space and now i believe ashok is going to talk about how we can run playing control on top of it [Applause]
Ashok Kumar Elluswamy (lead in the Planning and Control, Auto Labeling and Simulation teams)
Planning and Control
Core Objective of the Car
So, like Andrej mentioned, the visual networks take dense video data and then compress it down into a 3d vector space. The role of the planner now is to consume this vector space and get the car to the destination while maximizing the safety, comfort and the efficiency of the car.
Even back in 2019 our planner was a pretty capable driver. It was able to stay in the lanes, make lane changes as necessary and take exits off the highway. But city driving is much more complicated. Rarely there are structured lane lines, vehicles do much more free form driving, the car has to respond to all of […] and crossing vehicles and pedestrians doing funny things.
What is the key problem in planning?
- The action space is very non-convex.
- It is high-dimensional.
What I mean by non-convex is, there can be multiple possible solutions that can be independently good, but getting a globally consistent solution is pretty tricky. So, there can be pockets of local minima that the planning can get stuck into.
Secondly the high-dimensionality comes because the car needs to plan for the next 10 to 15 seconds and needs to produce the position, velocities and acceleration or this entire window. This is a lot of parameters to produce at runtime.
Discrete search methods are really great at solving non-convex problems because they are discrete they don’t get stuck in local minima whereas continuous function optimization can easily get stuck in local minima and produce poor solutions that are not great.
On the other end for high-dimensional problems discrete search sucks because it is discrete it does not use any grid information. So, it literally has to go and explore each point to know how good it is, whereas continuous optimization uses gradient-based methods to very quickly go to a good solution.
Our Solution: A Hybrid Planning System
Our solution to the central problem is to break it down hierarchically. First is a coarse search method to crunch down the non-convexity and come up with a convex corridor, and then use continuous optimization techniques to make the final smooth trajectory. Let’s see an example of how the search operates.
So here, we’re trying to do a lane change. In this case, the car needs to do two back to back lane changes to make the left turn up ahead. For this, the car searches over different maneuvers. So, the first one, it searches a lane change that’s close by, but the car breaks pretty harshly, so it’s pretty uncomfortable. The next maneuver tries, that’s the lane change is a bit late, so it speeds up, goes beyond the other car, goes in front of the other cars and finally makes the lane change. But now it risks missing the left turn. We do 1000s of such searches in a very short time span. Because these are all physics based models, these features are very easy to simulate. And in the end, we have a set of candidates and we finally choose one based on the optimality conditions of safety, comfort and easily making the turn.
So now the car has chosen this path and you can see that as the car executes this trajectory, it pretty much matches what we had planned. The cyan plot on the right side here, that one is the actual velocity of the car. And the white line underneath, this was the plan. We are able to plan for 10 seconds here and able to match that when you see in hindsight. So, this is a well-made plan. When driving alongside other agents, it’s important to not just plan for ourselves. But instead, we have to plan for everyone jointly and optimize for the overall scene’s traffic flow. In order to do this, what we do is we literally run the Autopilot planner on every single relevant object in the scene. Here’s an example of why that’s necessary.
This is an auto corridor, I’ll let you watch the video for a second. Yeah, that was Autopilot driving an auto corridor going around parked cars, cones and poles. Here’s this 3D view of the same thing. The oncoming car arrives now, and Autopilot slows down a little bit, but then realizes that we cannot yield to them because we don’t have any space to our side. But the other car can yield to us instead. So instead of just blindly breaking here, Autopilot reasons about that car has low enough velocity that they can pull over and should yield to us, because we cannot yield to them and assertively makes progress.
A second oncoming car arrives now. This vehicle has higher velocity. And like I said earlier, we literally run the Autopilot trainer for the other object. So in this case, we run the planner for them. That object’s plan now goes around their site’s parked cars and then after they pass the parked cars goes back to the right side of the road for them. Since we don’t know what’s in the mind of the driver, we actually have multiple possible features for this car. Here, one feature is shown in red, the other one is shown in green. The green one is a plan that yields to us. But since this object’s velocity and acceleration are pretty high, we don’t think that this person is going to yield to us and they actually want to go around this parked cars. So, Autopilot decides that, okay, I have space here, this person is definitely going to come, so I’m going to pull over.
So as Autopilot is pulling over, we noticed that that car has chosen to yield to us based on their yaw rate and their acceleration, and Autopilot immediately changes its mind and continues to make progress. This is why we need to plan for everyone because otherwise we wouldn’t know that this person is going to go around the other parked cars and come back to that site. If you didn’t do this, Autopilot would be too timid, and it would not be a practical self-driving car. So, now we saw how the search and planning for other people set up a convex valley.
Finally, we do a continuous optimization to produce the final trajectory that the planner needs to take. Here, the gray thing is the convex corridor. And we initialize a spline in heading an acceleration parametrize over the arc length of the plan. And you can see that the continuous optimization continuously makes fine grained changes to reduce all of its costs.
Some of the costs for example, are distance from obstacles, traversal time, and comfort. For comfort, you can see that the latest acceleration plots on the right have nice trapezoidal shapes… – it’s going to come first… yeah, here on the right side, the green plot – that’s a nice trapezoidal shape. And if you record our human trajectory, this is pretty much how it looks like. The lateral jerk is also minimized. So, in summary, we do a search for both us and everyone else in the scene. We set up a convex corridor and then optimize for a smooth path. Together, these can do some really neat things like showing above.
But driving looks a bit different in other places, like where I grew up. It is very much more unstructured, cars and pedestrians cutting each other, arch breaking, honking. It’s a crazy world. And we can try to scale up these methods but it’s going to be really difficult to efficiently solve this at runtime. What we instead want to do is use learning based methods to efficiently solve them. And I want to show why this is true. And so we’re going to go from this complicated problem to a much simpler toy product parking problem, but it still illustrates the core of the issue.
Here, this is a parking lot. The ego car is in blue and needs to park in the green parking spot here. So, it needs to go around the curbs, the parked cars, and the cones shown in orange here. This is simple baseline. It’s an A* standard algorithm that uses a lattice based search. And the heuristic here is a distance, the Euclidean distance to the goal. So, you can see that it directly shoots towards the goal, but very quickly gets trapped in a local minima, and it backtracks from there and then searches a different path to try to go around this parked cars. Eventually, it makes progress and gets to the goal, but ends up using 400,000 nodes for making this.
Obviously, this is a terrible heuristic. We want to do better than this. So if you added a navigation route to it, and have the car to follow the navigation route, while being close to the goal, this is what happens. The navigation route helps immediately, but still, when you enter encounters, cones or other obstacles, it basically does the same thing as before, backtracks and then searches a whole new path. And the support search has no idea that these obstacles exist, it literally has to go there, check if it’s in collision, and if it’s in collision back up. The navigation heuristic helped, but still, this took 22,000 nodes.
We can design more and more of these heuristics to help the search make go faster and faster. But it’s really tedious and hard to design a globally optimal heuristic. Even if you had a distance function from the cones that guided the search, this would only be effective for a single cone. But what we need is a global value function. So instead, what we’re gonna use is neural networks to give this heuristic for us. The visual networks produce a vector space and we have cars moving around in it. This basically looks like an Atari game and it’s a multiplayer version. So, we can use techniques such as MuZero, AlphaZero, etc, that was used to solve Go, and other Atari games to solve the same problem.
So, we’re working on neural networks that can produce state and action distributions, that can then be plugged into Monte Carlo tree search with various cost functions. Some of the cost functions can be explicit cost functions like collisions, comfort, traversal time, etc. But they can also be interventions from the actual manual driving events. We train such a network for this simple parking problem. So here again, the same problem. Let’s see how MCTS tree search does [shows demo].
Here you notice that the planner is basically able to in one shot make progress towards the goal. To notice that this is not even here using a navigation heuristic. Just given the scene, the planner is able to go directly towards the goal. All the other options you’re seeing are possible options. It’s not using any of them. Just using the option that directly takes it towards the goal. The reason is that the neural network is able to absorb the global context of the scene, and then produce a value function that effectively guides it towards the global minima as opposed to getting sucked in any local minima. So, this only takes 288 nodes and several orders of magnitude less than what was done in the A* with the Euclidean distance heuristic.
So, this is what the final architecture is going to look like. The vision system is going to crash down the dense video data into a vector space. It’s going to be consumed by both an explicit planner and a neural network planner. In addition to this, the network planner can also consume intermediate features of the network. Together, this produces a trajectory distribution, and it can be optimized end to end both with explicit cost functions and human intervention and other limitation data. This then goes into explicit planning function that does whatever is easy for that and produces the final steering and acceleration commands for the car. With that, we need to now explain how we train these networks. And for training these networks we need large data sets. And Andrej now speaks briefly about manual labeling.
Andrej Karpathy
Manual Labeling
The story of data sets is critical of course so far we’ve talked only about neural networks but neural networks only establish an upper bound on your performance many of these neural networks uh they have hundreds of millions of parameters and these hundreds of millions of parameters they have to be set correctly if you have a bad setting of parameters it’s not going to work so neural networks are just an upper bound you also need massive data sets to actually train the correct algorithms inside them now in particular i mentioned we want data sets directly in the vector space and so the really the question becomes how can you accumulate because our networks have hundreds of millions of parameters how do you accumulate millions and millions of vector space examples that are clean and diverse to actually train these neural networks effectively now so there’s a story of data sets and how they’ve evolved on the side of uh all of the models and developments that we’ve achieved now in particular when i joined roughly four years ago we were working with a third party to obtain a lot of our data sets now unfortunately we found very quickly that working with a third party to get data sets for something this critical was just not going to cut it the latency of working with a third party was extremely high and honestly the quality was not amazing and so in the spirit of full vertical integration at tesla we brought all of the labeling in-house and so over time we’ve grown more than one thousand person uh data labeling org that is full of professional labelers who are working very closely with the engineers so actually they’re here in the u.s and co-located with the engineers here in the area as well and so we work very closely with them and we also build um all of the infrastructure for them from scratch ourselves so we have a team we are going to meet later today that develops and maintains all of this infrastructure for data labeling and so here for example i’m showing some of the screenshots of some of the latency throughput and quality statistics that we maintain about all of the labeling workflows and the individual people involved and all the tasks and how the numbers of labels are growing over time so we found this to be quite critical and we’re very proud of this now in the beginning roughly three or four years ago most of our labeling was in image space and so you can imagine that this is taking quite some time to annotate an image like this and this is what it looked like where we are sort of drawing polygons and polylines on top of on top of these single individual images as i mentioned we need millions of vector space labels so this is not going to cut it so very quickly we graduated to three-dimensional or four-dimensional labeling where we are directly labeling in vector space not in individual images so here what i’m showing is a clip and you are seeing a very small reconstruction you’re about to see a lot more reconstructions soon but it’s very small reconstruction of the ground plane on which the car drove and a little bit of the point cloud here that was reconstructed and what you’re seeing here is that the labeler is uh changing the labels directly in vector space and then we are reprojecting those changes into camera images uh so we’re labeling directly in vector space and this gave us a massive increase in throughput for a lot of our labels because you’re labeled once in 3d and then you get to reproject but even this we realized was actually not going to cut it so because people and computers have different pros and cons so people are extremely good at things like semantics but computers are very good at geometry reconstruction triangulation tracking and so really for us it’s much more becoming a story of how do humans and computers collaborate to actually create these vector space data sets and so we’re gonna not talk about auto labeling which is some of the infrastructure we’ve developed for labeling these clips at scale [Applause]
Ashok Kumar Elluswamy
Auto Labeling
Even though we have lots of human labelers the amount of training data needed for training with networks significantly outnumbers them. So, we try to invest in a massive auto labeling pipeline. here’s an example of how we label a single clip a clip is a entity that has dense sensor data like videos imu data gps odometry etc this can be 45 second to a minute long these can be uploaded by our own engineering cars or from customer cars we collect these clips and then send them to our servers where we run a lot of neural networks offline to produce intermediate results like segmentation masks depth point matching etc this then goes through a lot of robotics and a algorithm to produce a final set of labels that can be used to train the networks one of the first tasks we want to label is the road surface typically we can use splines or meshes to represent the road surface but those are because of the topology restrictions are not differentiable and not amenable to producing this so what we do instead is in the style of neural radiance fields work from last year which is quite popular so we use an implicit representation to represent the road surface here we are querying xy points on the ground and asking for the network to predict the height of the ground surface along with various semantics such as curves lane boundaries road surface rival space etc so given a single xy we get a z together these make a 3d point and they can be reprojected into all the camera views so we make millions of such queries and get lots of points these points are reprojected into all the camera views in we are showing on the top right here one such camera image with all these points reprojected now we can compare this point reprojected point with the image space prediction of the segmentations and jointly optimizing this or all the camera views was across space and time produced an excellent reconstruction here’s an example of how that looks like so here this is an optimized road surface that reproduction to the eight cameras that the car has and across all of time and you can see how it’s consistent across both space and time so a single car driving through some location can sweep out some patch around the trajectory using this technique but we don’t have to stop there so here we collect collected different clips from the same location from different cars maybe and each of them sweeps out some part of the road cool thing is we can bring them all together into a single giant optimization so here these 16 different trips are organized using aligned using various features such as roadages lane lines all of them should agree with each other and also agree with all of their image space observations together this is this produces an effective way to label the road surface not just where the car drove but also in other locations that it hasn’t driven it again the point of this is not to just build hd maps or anything like that it’s only to label the clips through these intersections so we don’t have to maintain them forever as long as the labels are consistent with the videos that they were collected at optionally then humans can come on top of this and clean up any noise or additional metadata to make it even richer we don’t have to stop at just the road surface we can also arbitrarily reconstruct 3d static obstacles um here this is a reconstructed 3d point cloud from our cameras the main innovation here is the density of the point cloud typically these points require texture to form associations from one frame to the next frame but here we are able to produce these points even on textual surfaces like the road surface or walls and this is really useful to annotate arbitrary obstacles that we can see on the scene in the world one more cool advantage of doing all of this on server on the servers offline is that we have the benefit of hindsight this is a super useful hack because uh say in the car then the network needs to produce the velocity it just has to use the historical information and guess what the velocity is but here we can look at both the history but also the future and basically cheat and get the correct answer uh of the kinematics like velocity acceleration etc one more advantage is that we can have different tracks but we can switch them together that even through occlusions because we know the future we have future tracks we can match them and then associate them so here you can see the pedestrians on the other side of the road are persisted even through multiple occlusions by these cars this is really important for the planner because the planner needs to know if it’s if it saw someone it still needs to account for them even then they are occluded so this is a massive advantage combining everything together we can produce these amazing data sets that annotate all of the road texture or the static objects and all of the moving objects even through occlusions producing excellent kinematic labels all you can see how the cards turn smoothly produce really smooth labels or the pedestrians are consistently tracked the park cars uh obviously zero velocity so we can also know that they are parked so this is huge for us this is one more example of the same thing you can see how everything is consistent we want to produce a million such uh labeled clips and train our video multicam video networks with such large data set and really crush this problem we want to get the same view that’s consistent that we’re seeing here in the car we started our first exploration of this with the remove the data project uh we removed it in a very top a short time span i think within three months in the early days of the network we noticed for example in low security conditions the network can suffer understandably because obviously this truck just dumped a bunch of snow on us and it’s really hard to see but we should still remember that this car was in front of us but our networks early on did not do this because of the lack of data in such conditions so what we did we added the fleet to produce lots of similar clips and the fleet responded it did so it produces um is it play yeah it produces lots of video clips where shit’s falling out of all other vehicles and we send this through our auto living pipeline that was able to label 10k clips in within a week this would have taken several months with humans labeling every single clip here so we did this for 200 of different conditions and we were able to very quickly create large data sets and that’s how we were able to remove this so once we train the networks with this data you can see that it’s totally working and keeps the memory that the subject was there and provides this.
Simulation
so finally we wanted to actually get a cyber truck into a data set for the remote radar can you all guess where we got this clip from i’ll give you a moment someone said it yes yes it’s rendered it’s our simulation it was hard for me to tell initially and i if i may if i may say so myself it looks pretty it looks very pretty um so yeah in addition to auto labeling we also invest heavily in using simulation for labeling our data so this is the same scene as seen before but from a different camera angle so a few things that i wanted to point out for example the ground surface it’s not a plane asphalt there are lots of cars and cracks and tower seams there’s some patchwork done on top of it vehicles move realistically the truck is articulated uh even goes over the curb and makes a wide turn um the other cars behave smartly they avoid collisions go around cars uh and also smooth and actual great smooth uh brake and accelerate smoothly the car here with the logo on the top is Autopilot actually auto part is driving that car and it’s making unproductive left hand and since it’s a simulation it starts from the vector space so it has perfect labels here we show a few of the labels that we produce these are vehicle cuboids with kinematics depth surface normals segmentation but andre can name a new task that he wants next week and we can very quickly produce this because we already have a vector space and we can write the code to produce these labels very very quickly so when does simulation help it helps number one when the data is difficult to source as large as our fleet is it can still be hard to get some crazy scenes like this couple and their dog running on the highway while there are other high-speed cars around this is a pretty rare scene i’d say but still can happen and Autopilot still needs to handle it when it happens when data is difficult to label um there are hundreds of pedestrians crossing the road this could be a mountain downtown people crossing the road it’s going to take several hours for humans to label this clip and even for automatic labeling algorithms this is really hard to get the association right and it can produce like bad velocities but in simulation this is trivial because you already have the objects you just have to spit out the cuboids and the velocities and also finally when we introduce closed loop behavior where the cars needs to be in a determining situation or the data depends on the actions this is pretty much the only way to get it reliably all this is great what’s needed to make this happen number one accurate sensor simulation again the point of the simulation is not to just produce pretty pictures it needs to produce what the camera in the car would see and other sensors would see so here we are stepping through different exposure settings of the real camera on the left side and the simulation on the right side we’re able to pretty much match what the real cameras do in order to do this we had to model a lot of the properties of the camera in our sensor simulation um starting from sensor noise motion blur optical distortions even headlight transmissions uh even like diffraction patterns of the windshield etcetera we don’t use this just for the Autopilot software we also use it to make hardware decisions such as lens design camera design sensor placement even headlight transmission properties second we need to render the visuals uh in a realistic manner you cannot have what in the game industry called jaggies these are aliasing artifacts that are dead giveaway that this is simulation we don’t want them so we go through a lot of paints to produce a nice special temple a special temporal anti-aliasing we also are working on neural rendering techniques to make this even more realistic yeah in addition we also use ray tracing to produce realistic lighting and global illumination okay that’s the last of the cop cars i think we obviously cannot have uh really just four or five cars because the network will easily overfit because it knows the sizes um so we need to have realistic assets like the moose on the road here um we have thousands of assets in our library and they can wear different shirts and actually can move realistically so this is really cool we also have a lot of different locations mapped and created uh to create these uh sim environments we have actually 2000 miles of uh road built and this is almost the length of the roadway from the east coast the west coast of the united states which i think is pretty cool in addition we have built efficient tooling to build several miles more on a single day on a for a single artist but this is just tip of the iceberg actually most of the data that we use to train is created procedurally using algorithms as opposed to artists making these simulation scenarios so these are all procedurally created roads with lots of parameters such as curvature various varying trees cones poles cars with different velocities and the interaction produce an endless stream of data for the network but a lot of this data can be boring because the network might already get it correct so what we do is we use also ml based techniques to basically put up the network to see where it’s failing at and create more data around the failure points of the network so this is in closed loop trying to make the network performance be better we don’t want to stop there so actually we want to create recreate any failures that happens to the Autopilot in simulation so that we can hold Autopilot to the same bar from then on so here on the left side you are seeing a real clip that was collected from a car it then goes through our auto labeling pipeline to produce a 3d reconstruction of the scene along with all the moving objects with this combined with the original visual information we recreate the same scene synthetically and create a simulation scenario entirely out of it so and then when we replay Autopilot on it Autopilot can do entirely new things and we can form new worlds new outcomes from the original failure this is amazing because we really don’t want Autopilot to fail and when it fails we want to capture it and keep it to that bar not just that we can actually take the same approach that we said earlier and take it one step further we can use neural rendering techniques to make it look even more realistic so we take the original original video clip we create a synthetic uh simulation from it and then apply neural rendering techniques on top of it and it produces this which looks amazing in my opinion because this one is very realistic and looks almost like it was captured by the actual cameras they saw results from last night because it was cool and we wanted to present it but yeah yeah i’m very excited for what sim can achieve but this is not all because network’s trained in the car already used simulation data we used 300 million images with almost half a billion labels and we want to crush down all the tasks that are going to come up for uh the next several months with that i invite milan to see uh to explain how we scale these operations and really build a label factory and spit out millions of labels [Applause]
Milan Kovac (integration of neural networks in the car, neural network training and evaluation infrastructure)
Hardware integration
So, tonight i’d just like to start by giving you some perspective into the amount of compute that’s needed to power this type of data generation factory. So, in the specific context of the push we went through as a team here a few months ago to get rid of the dependency on the radar sensor for the pilot we generated over 10 billion labels across two and a half million clips and so to do that we had to scale our huge offline neural networks and our simulation engine across thousands of gpus and just a little bit shy of 20 000 cpu cars on top of that we also included over 2000 actual Autopilot full self-driving computers in the loop with our simulation engine and that’s our smallest compute cluster so i’d like to give you some idea of what it takes to take our neural networks and move them in the car and so the the two main constraints that we’re working on there here are mostly latency and frame rate which are very important for safety but also to get proper estimates of acceleration and velocity of our surroundings and so the meat of the problem really is around uh the ai compiler that we write and extend here within the group that essentially maps the compute operations for my apart torch model to a set of dedicated and accelerated uh pieces of hardware and we do that while figuring out a schedule that’s optimized for throat put while working on their severe sram constraints and so by the way we’re not doing that just on one engine but on across two engines on the Autopilot computer and the way we use those engines here at tesla is such that at any given time only one of them will actually output control commands to the vehicle while the other one is used as an extension of compute but those roles are interchangeable both at the hardware and software level so how do we interact quickly together as a group through these ai development cycles well first we have been scaling our capacity to evaluate our software neural network dramatically over the past few years and today we’re running over a million evaluations per week on any code change that the team is producing and those evaluations runs on over three thousand actual footstar driving computers that are hooked up together in a dedicated uh cluster and so on top of this we’ve been developing really cool uh debugging tools and so here is a video of one of our tools which is uh helping developers uh iterate through the development of neural networks and comparing live uh the outputs from different revisions of the same neural network model as reiterating life through a video clips and so last but not least uh we’ve been scaling our neural network training compute dramatically over the past few years and today we’re barely shy of 10 000 gpus which just to give you some sense in terms of number of gpu is more than the top five publicly known supercomputers in the world but that’s not enough and so i’d like to invite ganesh to talk about the next steps [Applause]
Ganesh Venkataramanan (lead project Dojo)
Dojo
thank you milan my name is ganesh and i lead project dojo it’s an honor to present this project on behalf of the multidisciplinary tesla team that is working on this project as you saw from milan there’s an insatiable demand for speed as well as capacity for neural network training and elon prefetched this and a few years back he asked us to design a super fast training computer and that’s how we started project dojo our goal is to achieve best ai training performance and support all these larger more complex models that andres team is dreaming of and be power efficient and cost effective at the same time so we thought about how to build this and we came up with a distributed compute architecture after all all the training computers out there are distributed computers in one form or the other they have compute elements in the box out here connected with some kind of network in this case it’s a two-dimensional network but it could be any different network cpu gpu accelerators all of them have compute little memory and network but one thing which is common trend amongst this is it’s easy to scale the compute it’s very difficult to scale up bandwidth and extremely difficult to reduce latencies and you’ll see how our design point catered to that how our philosophy addressed these aspects of traditional limits for dojo we envisioned a large compute plane filled with very robust compute elements backed with large pool of memory and interconnected with very high bandwidth and low latency fabric and in a 2d mesh format and on to this for extreme scale big neural networks will be partitioned and mapped to extract different parallelism model graph data parallelism and then in neural compiler of ours will exploit spatial and temporal locality such that it can reduce communication footprint to local zones and reduce global communication and if we do that our bandwidth utilization can keep scaling with the plane of compute that we desire out here we wanted to attack this all the way top to the bottom of the stack and remove any bottlenecks at any of these levels and let’s start this journey in an inside out fashion starting with the chip as i described chips have compute elements our smallest entity or scale is called a training node and the choice of this node is very important to ensure seamless scaling if you go too small it will run fast but the overheads of synchronization will end software will dominate if you pick it too big it will have complexities in implementation in the real hardware and ultimately run into memory bottleneck issues because we wanted to address we wanted to address latency and bandwidth as our primary optimization point let’s see how we went about doing this what we did was we picked the farthest distance a signal could traverse in a very clock very high clock cycle in this case two gigahertz plus and we drew a box around it this is the smallest latency that a signal can traverse one cycle at a very high frequency and then we filled up the box with wires to the brink this is the highest bandwidth you can feed the box with and then we added machine learning compute underneath and then a large pool of sram and last but not the least a programmable core to control and this gave us our high performance training node what this is is a 64-bit superscalar cpu optimized around matrix multiply units and vector cmd it supports floating point 32 b float 16 and a new format cfp8 configurable fp8 and it is backed by one and a quarter megabyte of fast ecc protected sram and the low latency high bandwidth fabric that we designed this might be our smallest entity of scale but it packs a big punch more than one teraflop of compute in our smallest entity of scale so let’s look at the architecture of this the computer architects out here may recognize this this is a pretty capable architecture as soon as you see this it is a super scalar in order cpu with four wide vector and two wide vect two wide uh four wide scaler and two wide vector pipes we call it in order although the vector and the scalar pipes can go out of order but for the purest out there we still call it in order and it also has four-way multi-threading this increases utilization because we could do compute and data transfers simultaneously and our custom isa which is the instruction set architecture is fully optimized for machine learning workloads it has features like transpose gather link traversals broadcast just to name a few and even in the physical realm we made it extremely modular such that we could start averting these training nodes in any direction and start forming the compute plane that we envisioned when we click together 354 of these training nodes we get our compute array it’s capable of delivering teraflops of machine learning compute and of course the high bandwidth fabric that interconnects these and around this compute array we surrounded it with high speed low power services 576 of them to to enable us to have extreme i o bandwidth coming out of this chip just to give you a comparison point this is more than two times the bandwidth coming out of the state-of-the-art networking switch chips which are out there today and network switch chips are supposed to be the gold standards for i o bandwidth if we put all of it together we get training optimized chip our d1 chip this chip is manufactured in seven nanometer technology it packs 50 billion transistors in a miserly 645 millimeter square one thing you’ll notice 100 of the area out here is going towards machine learning training and bandwidth there is no dark silicon there is no legacy support this is a pure machine learning machine and this is the d1 chip in a flip chip bga package this was entirely designed by tesla team internally all the way from the architecture to gds out and package this chip is like a gpu level compute with a cpu level flexibility and twice the network chip level i o bandwidth if i were to plot the i o bandwidth on the vertical scale versus teraflops of compute that is available in the state-of-the-art machine learning chips are there including some of the startups you can easily see why our design point excels beyond power now that we had this fundamental physical building block how to design the system around it let’s see since d1 chips can seamlessly connect without any glue to each other we just started putting them together we just put 500 000 training nodes together to form our compute plane this is 1500 d1 chips seamlessly connected to each other and then we add dojo interface process processors on each end this is the host bridge to typical hosts in the data centers it’s connected with pci gen4 on one side with a high bandwidth fabric to our compute plane the interface processors provide not only the host bridge but high bandwidth dram shared memory for the compute plane in addition the interface processors can also allow us to have a higher radix network connection in order to achieve this compute plane we had to come up with a new way of integrating these chips together and this is what we call as a training tile this is the unit of scale for our system this is a groundbreaking integration of 25 known good d1 dies onto a fan out wafer process tightly integrated such that it preserves the bandwidth between them the maximum bandwidth is preserved there and in addition we generated a connector a high bandwidth high density connector that preserves the bandwidth coming out of this training tile and this style gives us nine beta flaps of compute with a massive i o bandwidth coming out of it this perhaps is the biggest organic mcm in the chip industry multi-chip module it was not easy to design this there were no tools that existed all the tools were croaking even our compute cluster couldn’t handle it we had to our engineers came up with different ways of solving this they created new methods to make this a reality now that we had our compute plane tile with high bandwidth ios we had to feed it with power and here we came up with a new way of feeding power vertically we created a custom voltage regulator module that could be reflowed directly directly onto this fan out wafer so what did we did out here is we got chip package and we brought pcb level technology of reflow on fan art wafer technology this is a lot of integration already out here but we didn’t stop here we integrated the entire electrical thermal and mechanical pieces out here to form our training tile fully integrated interfacing with a 52 volt dc input it’s unprecedented this is an amazing piece of engineering our compute plane is completely orthogonal to power supply and cooling that makes high bandwidth compute planes possible what it is is a nine petaflop training tile this becomes our unit of scale for our system and this is real i can’t believe i’m holding nine petaflops out here and in fact last week we got our first functional training tile and on a limited limited cooling benchtop setup we got some networks running and i was told andre doesn’t believe that we could run networks till we could run one of his creations this is min gpt2 running on dojo do you believe it next up how to form a compute cluster out of it by now you must have realized our modularity story is pretty strong we just put together some tiles we just styled together tiles a two by three tile in a tray makes our training matrix and two trays in a cabinet give 100 petaflops of compute did we stop here no we just integrated seamlessly we broke the cabinet walls we integrated these styles seamlessly all the way through preserving the bandwidth there is no bandwidth divert out here there is no bandwidth clips all the tiles are seamlessly connected with the same bandwidth and with this we have an exopod this is one extra flop of compute in 10 cabinets it’s more than a million training nodes that you saw we paid meticulous attention to that training node and there are one million nodes out here with uniform bandwidth not just the hardware the software aspects are so important to ensure scaling and not every job requires a huge cluster so we plan for it right from the get go our compute plane can be subdivided can be partitioned into units called dojo processing unit a dpu consists of one or more d1 chips it also has our interface processor and one or more hosts and this can be scaled up or down as per the needs of any algorithm any network running on it what does the user have to do they have to change their scripts minimally and this is because of our strong compiler suite it takes care of fine-grained parallelism and mapping the pro problems of mapping the neural networks very efficiently onto our compute plane our compiler is uses multiple techniques to extract parallelism it can transform the networks to achieve not only fine-grained parallelism using data model graph parallelism techniques it also can do optimizations to reduce memory footprints one thing because of our high bandwidth nature of the fabric is enabled out here is model parallelism could not have been extended to the same level as what we can it was limited to chip boundaries now we can because of our high bandwidth we can extend it to training tiles and beyond thus large networks can be efficiently mapped here at low batch sizes and extract utilization and new levels of performance in addition our compiler is capable of handling high level dynamic control flows like loops if then else etc and our compiler engine is just part of our entire software suite the stack consists of a extension to pytarch that ensures the same user-level interfaces that ml scientists are used to and our compiler generates code on the fly such that it could be reused for subsequent execution it has a llvm backend that generates the binary for the hardware and this ensures we can create optimized code for the hardware without relying on even single line of handwritten kernel our driver stack takes care of the multi-host multi-partitioning that you saw a few slides back and then we also have profilers and debuggers in our software stack so with all this we integrated in a vertical fashion we broke the traditional barriers to scaling and that’s how we got modularity up and down the stack to add to new levels of performance to sum it all this is what it will be it will be a fastest ai training computer for x the performance at the same cost 1.3 x better performance per watt that is energy saving and 5x smaller footprint this will be dojo computer we are not done we are assembling our first cabinets pretty soon and we have a whole next generation plan already we are thinking about 10x more with different aspects that we can do all the way from silicon to the system again we will have this journey again we’re recruiting heavily for all of these areas thank you very much and next up elon will update us on what’s beyond our vehicle feet fleet for ai
Elon Musk
Tesla Bot
now unlike unlike dojo obviously that was not real uh so doj is real uh the tesla bot will be real um but basically if you think about what we’re doing right now with the cars tesla is arguably the world’s biggest robotics company because our cars are like semi-sentient robots on wheels and with the full self-driving computer essentially the the inference engine on the car which will keep evolving obviously and uh dojo and all the neural nets recognizing the world understanding how to navigate through the world uh it it kind of makes sense to put that onto a humanoid form they’re also quite good at sensors and batteries and actuators so we think we’ll probably have a prototype sometime next year that basically looks like this and it’s intended to be friendly of course and uh navigate through a world uh built for humans and uh eliminate dangerous repetitive and boring tasks um we’re setting it such that it is um at a mechanical level at a physical level you can run away from it and and most likely overpower it so hopefully that doesn’t ever happen but um you never know so it’s uh it’ll be a you know a light a light yeah five miles an hour you can get run faster than that’d be fine [Laughter] um so yes it’s a round uh 5.8 um has sort of a screen where the head is for useful information um but as otherwise basically got the Autopilot system in it so it’s got cameras got eight cameras and full-size driving computer and making use of all of the same tools that we use in the car so um i mean things i think that are really hard about uh having a useful humanoid robot is cannot navigate through the world without being explicitly trained i mean without explicit like uh line-by-line instructions um can you can you talk to it and say you know please uh pick up that bolt and uh attach it to the car with that wrench and it should be able to do that um it should be able to you know please you know please go to the store and get me the following groceries um that kind of thing so yeah i think we can do that um and yeah this i think will be quite quite profound because if you say like what is the economy it is uh at the foundation it is labor so what happens when there is uh you know no shortage of labor um that’s why i think long-term that there will need to be universal basic income yeah but but not right now because this robot doesn’t work so we just didn’t need a minute so um yeah but i think essentially in the future physical work will be a choice if you want to do it you can but you won’t need to do it and yeah i think it obviously has profound implications for the economy because given that the economy at its foundational level is labor i mean capital is capital equipment it’s just distilled labor then is there any actual limit to the economy maybe not so yeah join our team and help build this
Q&A
- Thanks to all the presenters that was just super cool to see everything i’m just curious at a high level and this is kind of a question for really anyone who wants to take it um to what extent are you interested in publishing or open sourcing anything that you do for the future?
- um well i mean it is fundamentally extremely expensive to create uh the system so uh somehow that has to be paid for i’m not sure how to pay for it if it’s fully open sourced um yeah unless people want to work for free but but i should say that uh this is if other car companies want to license it and use it in their cars that would be cool this is not intended to be just limited to tesla cars
- is for the dojo supercomputer so did you solve the compiler problem of scaling to these many nodes or is or if it is solved is it only applicable to dojo because i’m doing research in deep learning accelerators and getting the correct scalability or the distribution even in one ship is extremely difficult from the research projects perspective so i was just curious
- excuse me mike for bill you, [Bill] have we solved the problem? not yet. Are we confident we will solve the problem? Yes, we have demonstrated networks on prototype hardware now we have models performance models showing the scaling the difficulty is as you said how do we keep the localities if we can do enough model parallel enough data parallel to keep most of the things local we just keep scaling we have to fit the parameters in our working set in our sram that we have and we flow through the pipe there’s plenty of opportunities sorry as we get further scale for further processor nodes have more local memory memory trade also bandwidth we can do more things but as we see it now the applications that tesla has we see a clear path [Ganesh] and our our modularity story means we can have different ratios different aspects created out of it i mean this is something that we chose for our applications internally [Elon] sure
- the locality portion of it given that training is such a soft scaling application uh even though you have all this compute and have a high bandwidth high bandwidth interconnect it it could not give you that performance because you are doing computations on limited memory at different locations so i was that’s very curious to me when you said it solved because i i just jumped onto the opportunity and would love to know more given that how much you can open source
- [Elon] yeah yeah i guess the proof’s in the pudding um so we should have dojo operational next year um and um i think we’ll we’ll obviously use it for uh training video training it’s i mean fundamentally this is about like um the the primary application initially is we’ve got vast amounts of video and how we train vast amounts of video uh as efficiently as possible and uh also shorten the amount of time like if you’re trying to train train to a task um like just in general innovation is um how many iterations and what is the average progress between each iteration and so if if you can reduce the time between iterations uh the rate of improvement is is much better so um you know if it takes like sometimes a couple days for a model to train versus a couple hours that’s a big deal but the the asset test here and um you know what i’ve told the dojo team is like it’s it’s successful if the uh software team wants to turn off the gpu cluster but if they want to keep the gpp cluster on it’s not successful so yeah
- hi right over here i love the presentation thank you for getting us out here loved everything especially the simulation part of the presentation i was wondering uh it looked very very very uh realistic are there any plans to maybe expand simulation to other parts of the company in any way?
- hi i’m ian glow uh i manage the Autopilot simulation team so as we go down the path to full self driving we’re gonna have to simulate more and more of the vehicle currently we’re simulating vehicle dynamics but we’re going to need bms we’re going to need the mcu we’re going to need every single part of the vehicle integrated and that actually makes the Autopilot simulator really useful for places outside of Autopilot so i want to expand or we want to expand eventually to being a universal simulation platform but i think before that we’re going to be spinning up a lot of optimist support and then a little bit further down the line that we have some rough ideas on potentially how to get uh the simulation infrastructure and some of the cool things we’ve built into the hands of people outside of the company [Elon] optimus is the code name for the tesla bot oops optimus subprime [Laughter]
- hi this is ali jahanian thank you for the great presentation and putting all of these cool things together yeah for a while i have been thinking that uh the car is already a robot so why not a humanity robot and i’m so happy that today you mentioned that you are going to build such thing especially i think that this can uh give opportunity for rays of uh putting multi modality together for instance we know that in the example that you are showed that there was a dog and with some passengers or running together the language and symbolic processing can really help for visualizing that so i was wondering if i could hear a little more about this type of putting modalities together including language and vision because i have been working with for instance mini gpt’s and andre put out there and yeah i had i didn’t hear much about other modalities that’s going into the car or at least in the simulation is is there any comment that you could tell us
- [Elon] well driving is fundamentally uh basically almost entirely vision neural nets uh like we’re basically it’s running on a biological vision neural net and what we’re doing here is a silicon camera neural net um so and there are there’s there is some amount of uh audio uh you know you want to hear uh if um there’s like emergency vehicles or uh you know uh i guess converse with the people in the car um you know if somebody’s yelling something at the at the car that car needs to understand what that is um so you know all things that are necessary for it to be fully autonomous yeah thank you
- hi uh thank you for all the great work that you’ve shown uh my question is for the team uh because the data that was shown was seems to be predominantly from the united states that the the fsd computer is being trained on but as it is being as it gets rolled out to different countries which have their own road systems and challenges that come with it how do you think that it’s going to scale like like i’m assuming like the ground up is not a very viable solution so how does it transfer to different countries uh well there is we actually do train on using data from probably like 50 different countries um but we have to pick you know in as we’re trying to advance full self driving we need to pick one country and since we’re located here we pick the us um and then we get a lot of questions like why not even canada like well because the roads are a little different in canada different enough um and so when trying to solve a hard problem uh you want to uh say like okay what’s the let’s not add additional complexity right now uh let’s just solve it for the us and then we’ll extrapolate to the rest of the world but we do use video from all around the world yeah i think a lot of a lot of what we are building is very country agnostic fundamentally all the computer vision components and so on don’t care too much about country specific uh sort of features every you know different countries have roads and they have curbs and they have cars and everything we’re building is fairly general for that yeah and there’s the the prime directive is don’t crash right and that’s true for every country yes this is the prime directive um and um even right now the car is pretty good at not crashing um and so just basically um whatever it is don’t hit it even if it’s a ufo that crash landed uh on the highway and still don’t hit it you should not need to recognize it in order to not hit it so that’s very important and i want to ask that when you do the photometric process multiview geometry how much of an error do you see is it like one millimeter one centimeter so i’m just if it’s not confidential sorry question what is the what’s it what’s the difference between the synthetic sure what is the difference between the synthetically created geometry to the actual geometry yeah it’s usually within a couple centimeters three or four centimeters that’s the standard deviation merge with different kind of modalities to bring down that error we primarily try to find scalable ways to label um in some occasions we use other sensors to help benchmark but we primarily use cameras for this system okay thanks yeah i i mean i think we want to aim for the car to be positioned uh accurately to the the sort of centimeter level um you know something on that order obviously it will depend on distance like close by things can be much more accurate than farther away things because and they would matter less because the car doesn’t have to make decisions much farther away and as it comes close it will become more and more accurate exactly a lot of questions thanks everybody my question has to do with sort of ai and manufacturing it’s been a while since we’ve heard about the alien dreadnought concept is the humanoid that’s behind you guys is that kind of brought out of the production health timeline and saying that humans are underrated in that process um well sometimes like some you know something that i say is uh taken to too much of an extreme there there are parts of the tesla system that are almost completely automated and then there are some parts that are almost completely manual and if you were to walk through the whole production system you would see a very wide range from yeah like i said fully automatic to almost completely manual but the vast majority it’s most of it is is already uh automated um so and then with the some of the design architecture changes like going to large aluminum high pressure die cast components we can take the entire rear third of the car and cast it as a single piece and now we’re going to do that the front third of the car is a single piece so the the body line um drops by like 60 to 70 percent in size um but yeah the the robot is not is not prompted by specifically by manufacturing needs it’s it’s just that we’re just obviously making the pieces that are needed for a useful humanoid robot so i guess we probably should make it and if we don’t someone else would well and so i guess we should make it and make sure it’s safe i should say like also manufacturing volume manufacturing is extremely difficult um and underrated and we’ve gotten pretty good at that it’s also important for that humanoid robot like how do you make the human robot not be super expensive and hi uh thank you for the present presentation and my question will be about skilling of dojo and uh in particular how do you scale the compute nodes in terms of thermal thermals and power delivery because there is only so much heat that you can dispense and only so much power that you can bring to like cluster rack and how do you want to scale it and how do you point to scale it in multiple data centers sure hi i’m bill i one of the dojo engineers the um so from a thermal standpoint and power standpoint we’ve designed it very modular so what you saw on the compute tile that will that will cool the entire tile so we we once we hook it up to it is liquid cooled on both the top and the bottom side um it doesn’t need anything else and so when we talk about clicking these together once we click it to power and we once we click it to um cooling it will be fully powered and fully cooled and all of that is less than a cubic foot yeah so tesla has a lot of expertise in power electronics and in uh in cooling so we took uh the power electronics expertise from the vehicle powertrain and the sort of the advanced cooling that we developed for the power electronics and for the vehicle and applied that to the super computer because as you point out uh getting heat out is extremely important just really heat limited so um yeah so it’s funny that like at the compute level it’s operating at less than a volt which is a very low voltage there’s a lot of amps so therefore a lot of heat i squared r is what really bites you on the ass um hi uh my question’s also similarly a question of scaling um so it seems like a natural consequence of using you know significantly faster training hardware is that you’d be either training models over a lot more data or you’d be training a lot more complex models which would be potentially significantly more expensive to run at inference time on the cars uh i guess i was wondering like if there was a plan to like also um apply dojo as something that you’d be uh using like on the self-driving cars and if so like you know do you foresee additional challenges there i can so as you could see like android’s models are not just for cars like there are auto labeling models there are other models that are like beyond car application but they feed into the car stack so so dojo will be used for all of those too not just the car inference part of the training yeah i mean the dojo’s first application will be consuming video data for training for that would then be run in the inverse inference engine on the car but uh and that i think is an important uh test to see if it actually is good or but is it actually better than gpu cluster or not um so but then beyond that it’s basically a general a generalized neural net training computer but it’s very much optimized to be a neural net so you know cpus and gpus uh they’re they’re they’re not made to be um they’re not they’re not designed specifically for training neural nets um we’ve been able to make gpus especially very efficient for portraying neural nets but that’s not that was never their design intent so it’s it’s bc gpus are still essentially running it uh neural net training in emulation mode so um with with dojo we’re saying like okay let’s just let’s just asic the whole thing let’s just have this thing that’s it’s built for one purpose and that is neural net training and just generally any system that is designed for a specific purpose will be better than one that is designed for a general purpose hey i had a question here hi um so you described two separate systems one was for vision therefore planner and control um does dojo love you train networks that cross that boundary and second thing is if you were able to train such networks would you have the onboard compute capability in the fst system to be able to run that in in under your tight latency constraints thanks yeah i think we should be able to train uh planner networks on dojo or any gpus it’s really invariant to the platform um and i think uh if anything once we make this entire thing end to end it’ll be more efficient than decoding a lot of these intermediate states so you should be able to run faster if you make the entire thing uh into in your neural networks we can avoid a lot of decoding of the intermediate states and only decode essential things required for driving the car yep certainly and to endness and as the guiding principle behind a lot of the network developments and over time in the stack neural networks have taken on more and more functionality and so we want everything to be trained end-to-end because we see that that works best but we are building it incrementally so right now the interface there is vector space and we are consuming it in the planner but nothing really fundamentally prevents you from actually taking features and eventually fine-tuning end-to-end uh so i think that’s definitely where this is headed yeah and the discovery really is like what are the right architectures that we need to place in network blocks to make it amenable to the task so like on a describe we can place spatial rnns to help with the uh perception problem uh and now it’s just neutral network so similarly for planning we need to bake in search and optimization into the planning into the network architecture and once we do that you should be able to do planning very quickly uh similar to c plus plus algorithms okay okay i think i had a question very similar to what he was asking about it seems like a lot of neural nets around computer vision and kind of traditional planning you had model predictive control in solving convex optimization problems very quickly and i’d wonder if there’s a compute architecture that’s more suited for convex optimization or the model predictive control uh solutions very quickly yeah 100 if you want to bake in like i said earlier if you want to bake in these architectures that do say model protein control but just like replace some of the blocks with neural networks or if we know the physics of it we can also use physics-based models part of the neural network’s forward pass itself so we are going to go towards a hybrid system where we will have neural network blocks placed together with a physics-based blocks and more networks later so it’ll be a hybrid stack and what we know to do well we place with explicitly and what the networks are created we’ll use the networks to optimize this uh so better end-to-end stack with this architecture baked in i i mean i do think that so as long as you’ve got like um surround video uh neural nets for understanding what’s going on and can uh convert those surround video into vector space then you basically have a video game um and if you know if you it’s like if you’re in grand theft auto whatever you can you can make the cars drive around and pedestrians walk around without crashing so um you can do you don’t have to have a neural net for control and planning um but it’s probably ultimately better um so but i think you can probably get to in fact i’m sure you can get to much safer than human with control and planning primarily in c plus plus with perception vision in neural nets hi my question is we’ve seen other companies for example use reinforcement learning and machine learning to optimize power consumption and data centers and all kinds of other internal processes my question is are is tesla using machine learning within its manufacturing design or other engineering processes i i discourage use of machine learning because it’s really difficult unless you basically unless you have to use machine learning don’t do it it’s usually a red flag when somebody says we want to use machine learning to solve this test i’m like that sounds like um so uh 99.9 percent of time you do not need it um so yeah but so it’s kind of like a you you reach for machine learning when you when you need to not but it’s i’ve not found it to be a convenient easy thing to do um it’s a super hard thing to do that may change if you’ve got a humanoid robot that can you know understand normal instructions um but yeah generally minimize use of machine learning in the factory hi um based on your videos from the simulator uh it looked like a combination of graphical and neural approaches i’m curious what the set of underlying techniques uh that are used for your simulator and specifically for neural rendering if you can share yeah so we’re doing uh at the bottom of the stack it’s just traditional game techniques uh just rasterization real time uh you know very similar to what you’d seen like gta on top of that we’re doing real-time ray tracing and then those results were really hot off the press um i mean we had that little asterisk at the bottom that that was from last night we’re going into the neural rendering space we’re trying out a bunch of different things we want to get to the point where the neural rendering is the the cherry on the top that pushes it to the point where the models will never be able to overfit on our simulator currently we’re doing things similar to photorealism enhancement there’s a paper a recent paper photo enhancing photo realism enhancement but we can do a lot more than what they could do in that paper because we have way more labeled data way more compute and also much we have a lot more control over environments and we also have a lot of people who can help us make this run at real time um but we’re going to try whatever we can do to get to the point where we can train everything just with the simulator uh if we had to but we will never have to because we have so much real world data that no one else has it’s just to fill in the little gaps in the real world yeah i mean the simulator is very helpful when there’s like these rare cases like like um you know like collision avoidance right before an accident um and then ironically that the better our cars become at avoiding accidents the fewer accidents there are so then our training set is small so then we have to make them crash in the simulation so it’s like okay minimize potential injury to uh pedestrians and people in the car you have five meters you’re traveling at you know 20 meters per second um take what actions would minimize probability of injury we can run that in some cars driving down the wrong side of the highway that kind of thing happens occasionally but not that often um for your humanoid contacts i’m wondering if you’ve decided on what use cases you’re gonna start with and what the grand challenges um are in that context to make this viable well i think for the humanoid for the tesla bot um optimus it’s basically going to start with just dealing with work that is boring repetitive and dangerous basically what is the work that people would least like to do um hi um so quick question about your simulations um obviously they’re not perfect right now so are you using any sort of domain adaptation techniques to basically bridge the gap between your simulated data and your actual real-world data because i imagine it’s kind of dangerous to just deploy models which are solely trained on simulated data so maybe some sort of explicit domain adaptation or something is that going on anywhere in your pipeline so currently uh i mean we’re producing the videos straight out of the simulator uh the the full clips of kinematics and everything and then we’re just immediately training on them but it’s not the entire data set it’s just a small targeted segment and we only are evaluating based on real world video um we’re paying a lot of attention to make sure we don’t ever fit uh and if we have to start doing fancier things we will but currently it’s we’re not having an issue with it overfitting on the simulator we will as we scale up the data um and that’s what we’re hoping to use neural rendering to bridge that gap to push that even further out um we’ve already done things where we’re using like the same networks in the car but retrain it to detect sim versus rail to drive our art decisions um and that’s actually helped um prevent some of these things as well yeah just to emphasize that overwhelmingly the data set is the real video from the cars on the actual roads uh nothing’s weirder or uh or has more corner cases than reality um it’s gets really strange out there but but then if if we find say a few examples of something very odd and there’s some very some for some very odd pictures we’ve seen then in order to train it effectively we want to create simulations uh say a thousand simulations that are that are variants of that quirky thing that we saw the foot to fill in the some important gaps and and make the system better and really all of this is about over time just reducing the probability of of a crash or an injury and it’s called the march of nines like how do you get to 99.999999 uh safe you know and it yeah each nine is an order of magnitude difficulty increase uh thanks so much for the presentation i was curious about the tesla bot um specifically i’m wondering if there are any specific applications that you think the humanoid form factor lends itself to and then secondary um because of its human form factor is emotion or companionship at all thought about on the product roadmap at all um well we certainly hope this does not feature in a dystopian sci-fi movie but uh you know like really at this point we’re saying like maybe this robot can just we’re trying we’re trying to be as literal as possible can it do um boring dangerous repetitive jobs that people don’t want to do and uh you know once you can have it do that then maybe you can do other things too but that’s the that’s the thing that we really great to have so it could be your buddy too i mean buy one and have it be or your friend and whatever i’m sure that people think of some very creative uses so uh so um so firstly thanks for the the really incredible presentation um my question is on the ai side um so one thing we’ve been seeing is that with some of these language modeling ais we’ve seen that scaling has just had incredible impacts in their capabilities and what they’re able to do so i was wondering whether you’re seeing similar kinds of effects of scaling in in your neural networks in your applications absolutely a bigger network typically we see it performs better provided you have the data to also train it with and this is also what we see for ourselves definitely in the car we have some latency consideration to be mindful of and so there we have to get creative to actually deploy much much larger networks but as we mentioned we don’t only train neural networks for what goes in the car we have these um auto labeling pipelines that can utilize models of arbitrary size so in fact we’ve traded a number of models that are not deployable that are significantly larger and work much better because we want 100 like we want much higher accuracy for the auto labeling and so we’ve done a lot of that and there we definitely see this trend yeah the order labeling is uh an extremely important important part of this whole whole situation without the order labeling i think we would not be able to solve the self-driving problem it’s kind of a funny form of distillation where you’re using these very massive models plus the structure of the problem to do this reconstruction and then you distill that into neural networks that you deploy to the car but we basically have a lot of neural networks and a lot of tasks that are never intended to go into the car yeah and also as time goes on that you get new frames of information so you really want to make sure your computer is distributed across all the information as opposed to just taking a single frame and hogging on it for say 200 milliseconds you actually have newer frames coming in so you want to like use all of the information and not just use that one frame i think one of the things we’re seeing is that the car’s predictive ability is um is quite is eerily good um it’s really getting better than human in terms of predicting like you say like what predict what this road will look like out when it’s out of sight like it’s around the bend and it predicts the road with very high accuracy and you know predict pedestrians or cyclists wherever behind you know where to just see a little corner of the bicycle and a little bit through through the windows of the bus and its ability to predict things is going to be much better than humans like really way way beyond right yeah we see this often where we have something that is not visible but the neural network is making up stuff that actually is very sensible sometimes it’s eerily good and you have to like you’re wondering this is in the training set and actually actually in the limit you can imagine the neural net has enough parameters to potentially remember earth so in the limit it could actually give you the correct answer and it’s kind of like an hd map back baked into the weights of the neural net i have a question about the design of the tesla bot specifically in order uh how important is it to maintain that humanoid form to build hands with five fingers uh that also respects the weight limits could be quite challenging you might have to use cable driven and then that also causes all kinds of issues um i mean this is just going to be bought version one and we’ll see so the it’s it needs to be able to do things that that people do um and uh you know be a generalized you know humanoid robot um i mean you could make you potentially have it give it like you know two fingers and a thumb or something like that um you know for now we’ll we’ll give it five fingers and and see see if that works out okay it probably will it doesn’t need to be like uh you know have like incredible grip strength but it needs to be able to work with tools so and you know carry a bag that kind of thing all right thanks a lot for the presentation so an old professor of mine told me that um the thing he disliked a lot about his tesla was that the Autopilot ux didn’t really inspire much confidence in the system especially when like objects are spinning classifications are flickering i was wondering like even if you have a good self-driving system how are you working on convincing tesla owners other road users or other road users and just the general public that your system is safe and reliable well i think that’s that’s the cars a while back cars used to spend they don’t they don’t spin anymore not in the if you’ve seen the fsd beta videos they they’re they’re pretty solid um and they will be getting more solid yeah as him add more and more data and train these multi-camera networks like these are pretty decent actually just like few months old and it’s really improving it’s not a done product uh and that we’ve never minds we can clearly see how this is just going to be like perfect but perfect for space because why not uh all the information is that in the videos it should produce a given lots of data and good architectures um and this is just an intermediate point in the timeline i mean it’s clearly headed to way better than human without question my turn oh hi here um i was wondering if you could talk a little bit about the short to medium-term economics of the bot i guess i understand the long-term vision of replacing physical labor but i also think repetitive dangerous and boring tasks tend to not be so highly compensated and so i just don’t see how to reproduce uh you know start with a supercar and then break into like the lower end of the market how do you do that for a robot humanoid well i guess you’ll just have to see hello hi um i was curious to know how the car ai prioritizes occupant safety versus pedestrian safety and what thought process goes into like deciding how to make this into the ai well i mean we the the thing to appreciate is that from the computer standpoint everything is moving slowly so uh think you know to a human uh things are moving fast to the computer they are not moving fast so i think this is in reality somewhat of a false dichotomy not that it will never happen but it will be very rare um you know if you think it was like you know going the other direction like rendering you know with full ray tracing uh neural net enhanced graphics on something like cyberpunk or in any you know advanced video game you know doing 60 frames a second uh perfectly rendered like how long would it take a person to even render one frame and without any mistakes can be done i mean it would take like a month just to just render one one frame out of 60 in a second in a video game it’s uh computers are fast and humans are slow i mean for example uh on on the rocket side the you you cannot steer the rocket to orbit um we actually hooked up a joystick to see if anyone could steal the rocket orbit but you need uh to react at roughly six seven hertz uh people can’t do it not even now that’s pretty low you know we’re talking more like even for like 30 hertz type of thing hi um with the over here uh with hardware 3 there’s been lots of speculation that with larger nets it’s hitting the limits of what it can provide how much headroom has the extended compute modes provided at what point would hardware 4 be required if at all well i’m confident that hardware 3 or the full stop driving computer 1 will be able to achieve full self driving at a safety level much greater than a human probably i don’t know at least two or three hundred percent better than a human um then obviously there will be a future hardware for or full self-driving computer too which we’ll probably introduce with the cybertruck um so maybe in about a year or so uh that is probably well that’ll be about four times more capable roughly um but it’s really just going to be like can we take it from say for argument’s sake 300 safer than a person to a thousand percent safer um you know just like there are people on the road who with with varying driving abilities but we still let people drive it you don’t have to be the world’s best driver to be on the road so as we see so yeah guess what’s new all um right are you worried at all since you don’t have any depth sensors on the car that people might try like adversarial attacks like printed out photos or something to try to trick the rgb neural network yeah like what pull some like wiley cody stuff you know like paint the tunnel on the on the wall it’s like oops um we haven’t really seen much of that um i mean for sure like like right now if you pr most likely if you had like a a t-shirt with a t-shirt with like a stop sign on it which i actually have a t-shirt with a stop sign on it and and then you like flash the car it will it will stop i i proved that um but we can obviously as we see these uh adversarial attacks then we can we train uh the cars to uh you know notice that well it’s actually a person wearing a t-shirt the stop sign on it so it’s probably not a real stop sign hi uh my question is about um the prediction and the planning i’m curious how do you incorporate uncertainty into your uh you know planning algorithms do you just basically assume you know you mentioned that you run the um the Autopilot for all the other cars on the road do you assume that they’re all going to follow those rules or are you accounting for the possibility that well they might be bad drivers for example yeah we do account for multi-modal futures it’s not that we just choose one we account for this person can actually do many things and we use that actual physics and kinematics to make sure that they’re not doing a thing that would interfere with us before we act um so if there’s any uncertainty we are conservative and then would yield to them of course there’s a limit to this because if you’re too conservative then it’s probably not practical so at some point we have to assert and we even then we make sure that the other person can yield to us and act sensibly i should say like um like before we introduce something into the fleet we will run it in shadow mode and so and we’ll see what what would this neural net for example have done in this particular situation um because and then effectively the drivers uh are training it training the net so if the neural net would have uh controlled and you know and say veered right but the person actually went left it’s like oh there’s a difference why was there that difference yeah and secondly all the human drivers are essentially training the neural net uh as to what is the correct course of action assuming it doesn’t then end up in a crash you know doesn’t count in that case yeah and secondly we have various estimates of uncertainty like flickr and when we observe this we actually uh say we are not able to see something we actually slow down the car to be again safe and get more information before acting uh yeah we don’t want to be brazen and just go into something that we don’t know about we only go into places where we know about yeah but um yeah it should be like aspirationally that the car should be the less it knows the sl you know the slower it goes yeah which is not true at some point but now yeah yeah we’ve yeah should we speed proportionate to confidence thanks for the presentation so i am curious appreciate the fact that the fsd is improving but if you have the ability to improve one component along the ai stack to present it today whether it is simulation data collections planning control et cetera which one in your opinion is going to have the biggest impact for the performance of the full self driving system it’s really the area under the curve of this like multiple points and if you improve anything uh it should improve the area i mean in the short term it’s arguably we need all of the nets to be um surround video uh and so we still have some legacy this is a very short term obviously we’re fixing it fast but there’s there’s still some nets that are not using surround video um and i think ideally that all use surround video yeah very yeah i think a lot of puzzle pieces are there for success we just need more strong people to also just help us make it work yeah that is the actual box so that is the actual bottleneck i would say i’m really one of the reasons that we are putting on this event exactly what well said andre that um there’s just a tremendous amount of work to do to make make it work so that’s why we need um talented people to join in and solve the problem uh thank you for the great presentation lots of my questions answered but one thing is uh when imagine that now you have a large amount of data even unnecessary how do you consider that like there’s a forgetting problem in neural networks like how are you considering those aspects and also another one are you considering online learning or continuous learning so that maybe each driver can have their version of uh self-driving software i think i think i know the literature that you’re referring to that’s not some of the problems that we’ve seen and we haven’t done too much continuous learning we train the system once we find in a few times that sort of goes into the car we need something stable that we can evaluate extensively and then we think that that’s good and that goes into cars so we don’t do too much learning on spot or continuous learning and don’t face the forgetting problem uh but there will be settings that you can say like if you do do you want are you typically a conservative driver or do you want to drive fast or slow you know it’s like i’m late for my i’m late for the airport uh could you go faster than you know basically the kind of instructions you’d give to your uber driver it’s like i’m late for the flight please hurry um or take it easy or you know whatever your style is so let’s take a few more questions here so and then we’ll call it a day all right so as our models have become more and more capable and i guess you’re deploying these models into the real world um one thing i guess that’s possible is for ai to become more i guess misaligned with what humans desire so i guess is that something that you guys are worried about as you guys deploy more and more robots um or do you guys like we’ll solve that problem when we get there yeah i think that we should be worried about ai um you know like what we’re trying to do here is i say narrow ai uh pretty narrow like just make the car drive better than a human um and then have the humanoid robot be able to do basic stuff um uh you know so um at the point at which you sort of start get uh superhuman intelligence uh yeah i don’t know all bets are off um but you know and that’s that’s that’s you know that’ll that’ll probably happen but but what we’re trying to do here at tesla is make useful ai that people love and and is unequivocally good that’s our you know try to aim for that okay maybe one more question hi uh my question is about the camera sensor in the beginning of the talk you had mentioned about building a synthetic animal and if you think about it a camera is a very poor approximation of a human eye and a human eye does a lot more than take a sequence of frames have you looked into like there are like these days are like cameras like event cameras have you looked into them or are you looking into a more flexible camera design or building your own camera for example well with hardware four we will we will have a next generation camera uh but i have to say that the the current cameras we have not reached the limit of the current cameras uh so um and i’m confident we can achieve full self-driving with much higher safety than humans with the current cameras and current compute hardware um but you know are we good to be a thousand percent better rather than 300 better so we’ll see continued evolution on on our levels and pursue that goal and i think in the future people will look back and say wow i can’t believe we had to drive these cars ourselves you know it’ll like self-driving cars will just be just a normal like self-driving elevators you know uh elevators used to have elevator operators and uh there’s someone there with like you know big big relay switch operating the elevator and then every now and then they’d get tired or you know some make a mistake and share somebody in half so um so now we uh you know we made elevators automatic and you just go and you press the button and you can be in a 100 story skyscraper and don’t really worry about it just go and press a button and the elevator takes you where you want to go but it used to be that all elevators were operated manually manually it’ll be the same thing like for cars all cars will be automatic and then um and electric obviously um so there will still be some gasoline cars and some manual cars just like there are still some horses so um all right well thanks everyone for coming and i hope you enjoyed a presentation and thank you for the great questions
HTML Elements
Below is just1 about everything you’ll need to style in the theme. Check the source code to see the many embedded elements within paragraphs.
Body text
Lorem ipsum dolor sit amet, test link adipiscing elit. This is strong. Nullam dignissim convallis est. Quisque aliquam.

This is emphasized. Donec faucibus. Nunc iaculis suscipit dui. 53 = 125. Water is H2O. Nam sit amet sem. Aliquam libero nisi, imperdiet at, tincidunt nec, gravida vehicula, nisl. The New York Times (That’s a citation). Underline.Maecenas ornare tortor. Donec sed tellus eget sapien fringilla nonummy. Mauris a ante. Suspendisse quam sem, consequat at, commodo vitae, feugiat in, nunc. Morbi imperdiet augue quis tellus.
HTML and CSS are our tools. Mauris a ante. Suspendisse quam sem, consequat at, commodo vitae, feugiat in, nunc. Morbi imperdiet augue quis tellus. Praesent mattis, massa quis luctus fermentum, turpis mi volutpat justo, eu volutpat enim diam eget metus.
Blockquotes
Lorem ipsum dolor sit amet, test link adipiscing elit. Nullam dignissim convallis est. Quisque aliquam.
List Types
Ordered Lists
- Item one
- sub item one
- sub item two
- sub item three
- Item two
Unordered Lists
- Item one
- Item two
- Item three
Tables
| Header1 | Header2 | Header3 |
|---|---|---|
| cell1 | cell2 | cell3 |
| cell4 | cell5 | cell6 |
| cell1 | cell2 | cell3 |
| cell4 | cell5 | cell6 |
| Foot1 | Foot2 | Foot3 |
Code Snippets
#container {
float: left;
margin: 0 -240px 0 0;
width: 100%;
}
Buttons
Make any link standout more when applying the .btn class.
<a href="#" class="btn btn--success">Success Button</a>
Notices
Watch out! You can also add notices by appending {: .notice} to a paragraph.
-
Texture image courtesty of Lovetextures ↩