Outline
I’m very excited to be here to tell you a bit more about how we’re scaling machine learning models data algorithms and infrastructure at Tesla and what that looks like. So, the outline of my talk is here I’d like to first tell you a little bit about Tesla Tesla autopilot what the feature set is really what the problem statement is what we’re trying to address here then I’ll tell you a bit about neural networks and what it takes to actually deploy them into production at scale and what that looks like for the team and then I’ll tell you a little bit more about some of the more recent neural networks that we have developed for the purposes of full self-driving I’ll go into that at the end.
Tesla Autopilot
So, first a little bit about Tesla and Tesla Autopilot. So, as you may know, it has a lot of manufactures and sells electric vehicles and we have an a whole array of electric vehicles some of them are in the hands of customers or imminently to be in the hands of customers and some of them have only been announced so for example we have the Model S the model 3 x and y and then we’ve also announced the cyber truck the ATV someone jokingly the Roadster and the semi and we have quite a few of these so globally we now have roughly 1 million cars and for the purposes of the team these are not just cars these are computers they’re internet accessible and we can both deploy over-the-air updates to them and get a lot of data from them that helps us develop the autopilot and they’re also robots so they have sensing they have actuation and we’re developing the brains of of that computer now the most basic kind of autopilot functionality is that when you turn it on in your car the car will keep its lane and it will keep distance away from the vehicle ahead of you we’ve now sort of accumulated almost 3 billion miles on the autopilot which sounds like a lot we then have more advanced features like such as for example navigating autopilot this allows you to set a pin somewhere in the world as a destination and then as long as you stick to the highway system the car will automatically reach that destination on the highway system it will do all the correct lane changes it will do it will take all the right Forks that interchanges and it will overtake slow vehicles ahead of you and it’s kind of like we think of it as roughly autonomy on the highway and the car now has to monitor its blind spot it has to have intelligence around where it is on the highway it has to localized the correct lane and so on we’ve also late last year released two smart summon this allows you to with your phone on the mobile app summon the car to you from a parking spot so if your car’s parked somewhere you just summon it to you and the car comes out of its parking spot with no one inside and comes wind its way through the parking lot to come find you it’s it’s quite magical when it works also under the hood we have a lot of active safety features that are always running and available even when our pal is not turned on and we have a lot of statistics available to us because we have 1 million cars in the road and we know how people get into trouble and then we try to implement features that you know help alert or avert an accident so for example automatic emergency braking front collision warning side collision warning blind spot monitoring lane departure avoidance emergency lane departure motions and so on these active safety features help keep customers save in our cars in particular on active safety we’re doing extremely well EuroNCAP awarded us with the 5-star rating in particular I believe we had the top scores and safety assist we also did extremely well on a B automatic emergency braking for pedestrians and cyclists now you’re seeing here for example a B pedestrian is five point six out of six points I think these numbers are kind of like a slightly abstract so let me actually put that in context like really what are we talking about here pedestrian a B is the following here’s a simple here’s one example the cars up someone just emerges from in between parked cars and this car may not have even been on the autopilot but we continuously monitor the environment around us we saw there’s a person in front and we slam on the brakes automatically here’s another example it looks like a pretty benign scene this person is probably not paying attention the pedestrian is not paying attention we slam on the brakes and prevent a collision here’s one more example you can see the trouble coming from the right it’s really hard to tell because everything is occluded and then suddenly there’s a pedestrian we slam on the brakes and a border collision again so you know five point six out of six it’s kind of abstract but we see a lot of these we see tens to hundreds of these per day where we actually are averting a collision and not all of them are true positives but a good fraction are and you know this is where you actually make your object detector really count here you’re really averting collisions now the gold the team hires to produce full self-driving functionality so here we have a video from the autonomy day that we had like somewhere early last year oops there we go so the ambition of the team is to produce full self-driving meaning that you can just set up in arbitrarily arbitrarily in the world not even on the highway system but everywhere else here you see the car just taking turns from the parking lot it comes to an intersection it waits for a yep green traffic light it turns to the left merges on the highway and no need to touch the wheel these this is not available to customers we only have developer builds that do these turns through intersections and so on but we’re trying to get it to the point where we feel that the system is accurate enough to actually release in some form so I’m going to cut this short but this will actually get on the cloverleaf in a bit it will take the cloverleaf it will turn around and come back to our headquarters in Palo Alto where a lot of the team is based now I’m gonna cut through this you may be asking like you saw the car take a left through an intersection when the light was green and you’ve actually seen a lot of these videos for a like a decade so you know here’s a way mo I just took a small clip away mo comes to an intersection and takes a look through the intersection you’ve seen this for a decade so how is this special why are we so late what’s taking so long and you know it looks the same so what’s the but I think the critical point to make is that it looks the same but under the hood it’s completely different in terms of the approach that we take towards fulsol driving so in particular we take a heavily vision-based approach so everyone else has a lidar on the top of the car the lidar shoots out lasers and creates a lidar point cloud map and then you pre map the environment that you’re going to drive so you have a high definition lighter map and you localize to it to ascending your level accuracy and then you know exactly the path you’re going to take so you can just steer to keep yourself you know perfectly localized in the correct region so this is quite helpful but this is not the approach that we take we do not have lidar on our cars so we don’t shoot our lasers it’s all camera based and we do not build high-definition maps so when we come to an intersection we encounter it basically for the first time we’ll come to an intersection how many lanes are there left right center which way should I turn what are the traffic lights which means do they control all this has just done just from camera feed a camera vision alone and so this is a bit of a harder problem but of course once you actually get this to work we can also deploy it to the millions of cars that we have globally so let me now tell you a little bit about the neural networks that actually support all of the features that I’ve shown you that the autopilot is capable of and what it takes to actually keep these neural networks in production at scale in the hands of customers so here’s a random scene where we have to potentially drive and wind our way through this scene as a human this is relatively effortless but you’re actually doing a lot under the hood and the autopilot has two as well so we understand a lot about what are the static objects what are the dynamic objects what is the road layout what is all of the layer of semantics on top of the road like Lane line markings road markings traffic lights that tell you about how you can actually traverse that scene so once you actually start writing down what’s necessary to actually you know perform the driving policy you end up with a long list of tasks all of which we need to actually handle and the detection of these tasks serves two purposes and two customers number one we actually need it for the driving policy and number two we actually want to show a lot of things on the instrument cluster for the human so that they gain sort of confidence in the system here we’ve produced a video that shows some of the under different predictions for the main camera that is facing forward on the car and you see that we’re detecting lanes were detecting stop sign over there stop line road markings we’re putting keyboards around the cars traffic lights Road edges and curbs even things like trash bins coming up over there lines that make up the intersection in a bit there’s lines that create parking spots we have to have all these attributes for whether or not a line is for a parking spot or not and things like that so these predictions were pretty DS but it’s actually a huge amount of work to get them to to actually work at scale and in the full long tail of what you can encounter on the roads so even taking a very simple task like for example stop sign you think that you know neural networks are capable of handling a thousands of categories of imagenet with all of their variations and so on so how difficult is it to just detect a fixed pattern of like red on white stop and it actually gets quite difficult when you get to the long tail of it even to create a simple detector first stop sign so first of all stop signs can of course be in lots of very environmental conditions stop signs can not just be impulse but kind of just like on walls stop signs can be temporary and just hang out in different configurations stop cells can have funny lights on them which are supposed to make it easier to see the stop sign but for our system is the opposite we have to actually explicitly worry about it stop signs can be held by a person that stop sign can be an in an inactive state or an active state stop signs can be on like these cones stop signs can be heavily occluded in lots of ways by foliage by signs stop signs can be occluded by cars stop signs can be part of cars and they can be part of cars in an active or inactive state again stops can be sort of held by person stops come with lots of exotic modifiers to them so this stop only applies except right turn this stop says take your turn through this place this stop is right turn keep moving so do not stop if you’re going right so there’s a variety of modifiers all of them we have to care about because they actually have impact on on how you should drive through this part of space and as I mentioned everything is a eye vision based at the moment we do have maps of course that we build but they’re not high-definition maps but stops can be attached to gates but they only apply when the gate is closed when it’s open they do not apply stops can be in arms these arms can lift and then the stop sign does not apply any more stops can only apply when you’re taking a left so their action conditional and so basically there’s a massive variety of even just for a stop sign to get this to work and what we do day to day in the team is we are going through the long tail and we’re building all this infrastructure for sourcing all these additional examples
Data Engine
And so I’ve shown in the Autonomy Day presentation earlier last year the data engine, the process by which we iteratively apply active learning to source examples in cases where the detector is misbehaving and then we source examples in those and we label them and incorporate them into a part of a training set. So for stop sign detection as an example we have an approximate detector for stop signs based on an initial seed set of data and we run that and deploy that to cars in shadow mode. And then you can detect some kind of a lack of health of that detector at test time. So, for example, the stop sign detection is flickering that could be a source of uncertainty. You can also detect that the neural network is uncertain in a certain Bayesian way and there’s a few ways to model that. You can find instances where you get surprised to see a stop sign, i.e. why didn’t you see it when you were a bit further away. You can also source examples when we detect a stop sign but the map thinks that there should be no stop sign or vice versa. So, if sort of a map-vision disagreement. So, we have lots of different ways of sourcing difficult cases and then we upload images and we look through them, we label some of them and incorporate them into our training set.
Heavily Occluded Stop Signs
As an example, we’ve struggled with these heavily occluded stop signs. We found that the detector was not performing very well when they were heavily occluded and that we have a mechanism in this data engine process where we can actually train these kinds of detectors offline so we can train a small detector that detects an occluded stop sign by trees and then what we do with that detector is that we can beam it down to the fleet and we can ask the fleet please apply this detector on top of everything else you’re doing and is that this detector scores high then please send us an image and then the fleet responds with somewhat noisy set but they boosted the amount of examples we have of stop signs that are occluded and maybe 10% of them are actual occluded stop signs that we get from that stream and this requires no firmware upgrade this is completely dynamic and can just be done by the team extremely quickly is the bread and butter of how we actually get any of these tasks to work just accumulating these large data sets in the full tail that distribution so we have tens of thousands of occluded stop signs the fleet can send us as many as it takes. We have the biggest data set for “except right turn” on “stops”. I’m basically certain of that. We again create a detector for this and then we get a noisy stream from the fleet of cars encountering “except right turn” on “stops” and we can label that, incorporate a new training set. We have tens of thousands of these. I’m not actually hundred percent sure how you built out a data set like this without the fleet.
Massage the Test Set
so I’ve talked a lot about massaging and growing the training sets but we place just as much we put just as much work into massaging the test sets as we do into training sets so just reporting your mean average precision or reporting the loss function that you achieve and a test set that just doesn’t do it for us so we spend a lot of time inspired by a serve test-driven development to build out very complicated unit tests and predicates for how the detector should behave in different cases so for example we could have a barrage of tests along the lines of in this image you should detect a stop sign right here and the modifier that you for this and that that you predict on the stop sign must be this or that and so we have mechanisms for creating and massaging and these unit tests it’s a growing collection as we encounter problems in the fleet and as we notice them and then we certify whether this detector is performing well or not and this is art this is really art doesn’t it’s curated unit tests if you’re in a production setting we actually like break down all this all these different issues and track them individually and then pursue them one by one with data engine to actually make them work so occluded size we would build out a test set first we see that we’re failing on occluded signs and then we once we have the test and we’re failing them we then spin the data engine on occluded size and then we see that the percent pass goes from 40 percent to 99 percent or something like that and then we’re confident that this is actually working relatively long now so I’ve kind of shown you a little bit of the process we take for even a very simple one prediction but as I mentioned there’s lots of tasks lots of attributes so the complexity of this is quite staggering we have to know a lot about any scene and each one of those things has their own data engine
HydraNet
so what we end up doing is we have these neural networks that have a shared backbone and then they’re multitask juggling lots of different tasks and in total the team is currently maintaining 48 networks that make a thousand distinct predictions these are just a raw number of output tensors if you just take all of our networks and you add up the output tensors it’s a thousand and those tensors of course can have multiple predictions in them none of these predictions can ever regress and all of them must improve over time and this takes 70,000 GPU hours the Train of the neural Nets if you have a node with a GPUs you will be trained for a year we do quite a bit of training there and all of this is not maintained by hundreds of people all of this is maintained by a small elite team of Tesla AI people basically like a few dozen so how’s it even possible to make progress and how’s it impossible that just small team can maintain so many tasks and get them to work over time.
Operation Vacation
The North Star for actually achieving this, for us, it’s called Operation Vacation which I’ll describe in a second. But basically the idea is that for any new task you have a latency to actually the task working. And there’s a process and we understand the process for getting a task to work. And we’re trying to develop as much automation machinery to actually support the development of these new features and new tasks. And we’re removing engineers from that loop, so they’re not involved. We’re just building out infrastructure and then we have a data labeling team and PMS and so on that can actually use that infrastructure to create new detectors. So, as an example, we’re working with caution lights recently. We’re trying to detect when the police car lights are turned on. This is an example of a new task that we’d like to know about. And we sort of have a cookie cutter. We know exactly what it takes to get a task to work, i.e. all the infrastructure is in place. So, this task, we’re going to treat it as a “landmark task”. “Landmark” is an example of a prototype, e.g. a detection prototype, a segmentation prototype, a landmark prototype. And these are just classes of tasks. And if your new task is an instance of any of these prototype classes, then all of the infrastructure is just plug-and-play and go through the full data engine, (i.e.) you can collect the seen data set, you label your examples, your source more examples in the cases where you’re failing, you deploy it in shadow mode, you source examples and you grind up metrics, you create all the unit test predicates. All this is completely automated. We’re mostly developing the automation infrastructure and then it’s easy to develop any new task. And that’s kind of how we get this to work.
Neural Networks for FSD
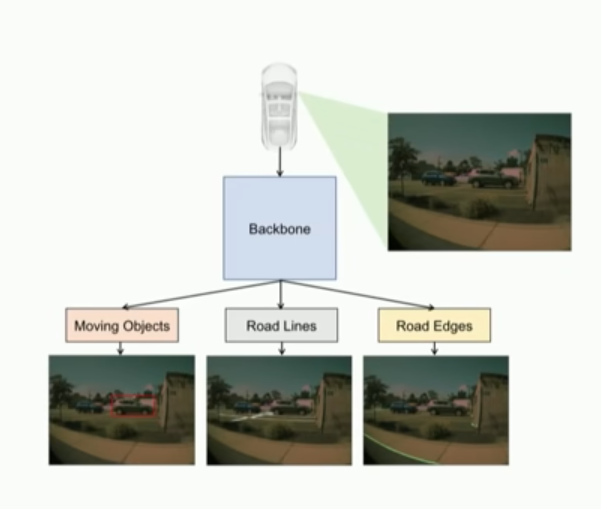
Okay, so now I’d like to talk a little bit about the neural networks and how they have to change to actually support full self-driving. So what I’ve explained so far as you take an image from one of the cameras you run it through this shared backbone and you make lots of predictions about it in the image pixel space. So, we can potentially predict objects, lines or edges and so on.

Taking the example of edges where does this go afterwards right so here’s a video and I’m showing the predictions of the road edge tasks on all of the different cameras and you can see that this is basically a binary segmentation problem for us and we detect those edges here and we use this to wind our way through a parking lot because we’d like to go to a certain destination but avoid all the raw edges.
Bird’s Eye View Projection (Occupancy Tracker)
Now, you can’t just drive on the raw predictions of these edges in these two-dimensional pixel coordinate systems. So, you have to somehow project this out into a bird’s eye view sort of.
![]()
In order to make this make sense. So, the raw detections we project them out into 3d and we stitch them up into what we call a “occupancy tracker”. So, this occupancy tracker takes all the raw measurements from the 2d images we project them out into the world and we stitch them up across cameras. And we stitch them up across time, so the occupancy tracker is keeping the temporal context of that. And it creates a small local map and then it winds its way through this parking lot to get to the person who is summoning the car at this time.
Stitching Multiple-View Camera Frames Problem
So this is all fine but there’s a lot of problems with actually doing the stitching as I’m describing it. I’m making it sound very easy. The problem is these cameras are pointed in arbitrary directions. They make these measurements in this pixel frames you might not your road edges might not even align across camera scenes and writing the tracker for these edges over time is actually highly non-trivial, lots of hyperparameters, error-prone code, very difficult to develop.
Software 2.0 in the Occupancy Tracker
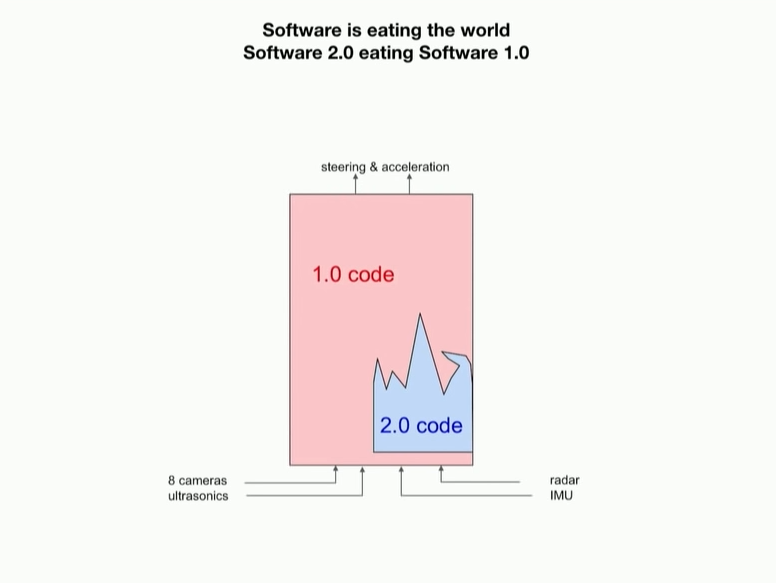
So, I’ve shown this example or this visualization a few times in many of my previous talks where this is sort of the autopilot software stack on the bottom you have inputs to the stack a primarily vision and on the output we have steering acceleration and roughly you can think of two code bases hidden inside the software stack we have what I refer to as a software 1.0 code which has good old fashioned C++ explicitly designed engineered by person person writes the code and then you have what I call software 2.0 code where the the code is an outcome of an optimization it’s a it’s the compilation it’s a compiler takes your data set and creates neural network code that runs in the car and so it’s roughly speaking your own that the reason I refer to it as software 2.0 is that you can take functionality from 1.0 code base and put it into 2.0 code base so this boundary is fluid and you can actually engulf more and more software 1.0 stack so over time since I joined about two and a half years ago the neural net have expanded in how much of software one panel and they’ve taken over and so the trend is upwards.
So, in particular, in the case of these road edges, as I have described, what we are now working towards is that we don’t actually want to go through this explicit occupancy tracker software 1.0 code. We’d like to engulf it into neural net code. And we see that typically that works really well.
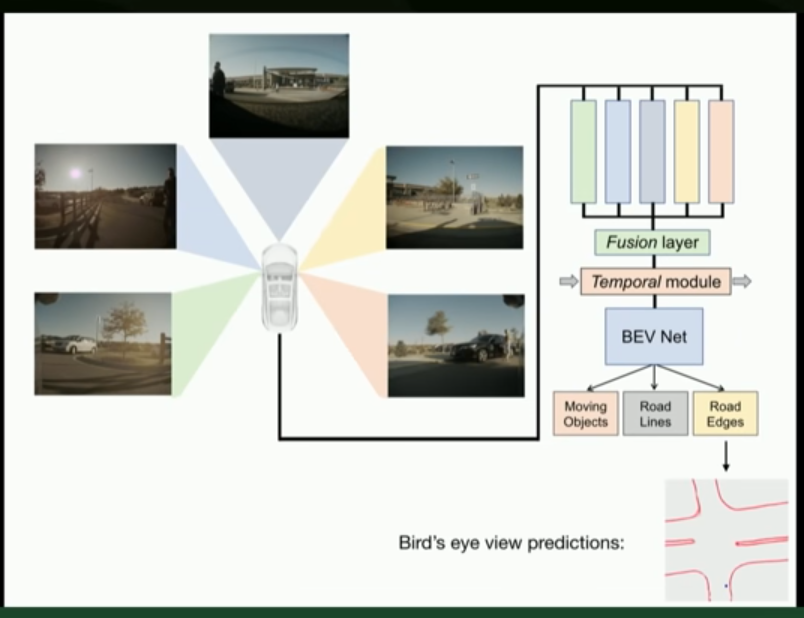
So, a lot of our networks have been moving towards these bird’s-eye view network predictions, where you take all these cameras and you feed them through backbones and then you have neural net fusion layer that stitches up the feature maps across the different views and also does the projection from image space to bird’s eye view. And then we have a temporal module potentially that actually smooths out these predictions. And this is all neural net components. And then we have a bed net decoder that actually creates the top-down space. And so, then we can directly potentially predict these road edges in a top-down view.

Now, this makes a huge difference in practice. So, here’s an example. In top row I’m showing the camera left, camera center, camera right. And I’m showing road edge detection in red.
On the bottom row on the left you see the ground truth of what this intersection looks like and you see that the cars position on the dot. And so that’s the ground truth.
On the very right you see what happens when you take 2d predictions in the images and you cast them out. You basically get garbage. Like it somewhat works around the car. There the projection is easy. But far away especially near the horizon line a few pixels of error means lots of meters of the error and so this projection based techniques are extremely hard to get to work. You’d have to know extremely accurate depth per pixel to do that projection. It’s a very hard problem.
And in the in the middle you are seeing some of our predictions from the recent bird’s eye view networks that just kind of make these predictions in top-down view directly.
Intersection in the Occupancy Tracker
Watch YouTube
So, let me show you a video here of what this looks like in practice.
On the top we will have a video of an intersection. On the bottom I’m showing some of the predictions achieved by the Tesla AI team that has produced these bird’s-eye view networks. We have rode edges in red. We have dividers in green on the very left. Then we have attributes for these dividers, i.e. we want to know if it’s an actual “curb” or if it’s just like a “logical curb”, so like a yellow line or something like that. Then we have a “traffic flow direction” and a few other things like that. I’m only showing some examples.
But the car is on the bottom center of these images and as we are turning through this intersection these birds-eye view Networks just predict pretty far away the full structure of this intersection and what it looks like. So, this is extremely powerful for us.
Parking Lot in the Occupancy Tracker
Here’s another example in the case of “smart summon”. The car is driving around parking lots and we have to understand the corridors of this parking lot. And so here we are predicting the corridors in bird’s-eye view. We’re predicting where the corridors meet at intersection points in red and we’re predicting tiny arrows that tell us the traffic flow and this all comes up the net directly there’s no occupancy tracker necessary.
Object Tracking in the Occupancy Tracker
Here’s an example of using this for objects. So on the top we have our camera feeds on the middle I’m showing our per pixel depth predictions achieved by via self-supervised learning we need those depth predictions because we take - as many others do in the literature right now - we take a pseudo lidar approach, where you basically a predict the depth for every single pixel and you can cast out your pixels and you basically simulate lidar input that way, but it’s purely from vision. And then you can use a lot of techniques that have been developed for Lidar processing to actually achieve 3d object detection. So, on the on the bottom you have them predictions of our detector directly in the bird’s eye view.
Pseudo-Lidar
Yeah, here I have one more slide showing just our depth predictions for some of some other videos this is not very exotic for any of you who are in computer vision because there are entire workshops and particularly on creating videos like these, where we are basically achieving depth directly from images and this is done, of course, no human can annotate depth, so this is done using self-supervised techniques. So, in particular, we take an image, we predict a depth. Then, when you have a depth for an image, you can cast out all the pixels into 3d and you can re-project them either into camera views at that same time but different cameras, or you can re-project them into the future frames of that single camera. And then you have a photometric loss that’s enforcing consistency. And, so, the only way to make everything consistent in re-projections is to predict the correct depth. And so, this learns in a self-supervised fashion to predict depth and then we can simulate Lidar inputs directly from vision and use this downstream to make these bird’s eye view predictions.
And as you might be familiar, the gap is quickly closing in state-of-the-art approaches. If you give yourself Lidar and how well you can do versus if you do not have lidar, but you just use vision techniques and you use pseudo lidar approaches, then that gap is quickly shrinking in academia. And we see a lot of this as well internally.
Outlook: Software 2.0 Planner
Finally, I’ve shown you sort of how this software 2.0 stack is expanding through the code it’s eating some of the you know occupancy tracker like techniques. The logical conclusion of that, of course, is there’s still a perception system that creates explicit predictions and those explicit predictions are
- shown in the instrument cluster and
- they are used for a policy. And this policy is still in the land of 1.0, where for us and for many others as well, where you have explicit planner that takes all the predictions and drives on that. The problem with that is your explicit predictions are basically doomed to never be good enough and never be complete. And so writing these planners is extremely difficult, error-prone, lots of hyperparameters, very tricky. And so the logical conclusion of this, of course, is that we’d like to train our networks to actually do a lot of this planning inside the network. In particular, we have huge data sets of people driving cars so when people drive cars and they steer the wheel they’re actually data labeling for you. They’re showing you how to drive through any into any intersection or any other kind of place.
Self-supervised Learning, Contrastive Learning
And the other thing I’ll say is like most of what I’ve described so far this relies primarily on self super part on the supervised learning with the exception of depth where we massage and create massive data set but but we’ve seen recently with the use of for example contrasted losses and things like that there’s a lot of progress today in cell supervised learning and so we’d like to leverage some of that in a team here’s an example of just some videos we have probably the most interesting largest data set of videos these are coming from cameras and so we’ve been really looking into some of these cell surprise techniques to speed up the process and to speed up the rate at which we learn from very little supervised data so we don’t have to collect like tens hundreds of thousands of examples of except right turn we can do it we prefer not to.
Join Tesla Autopilot
Okay so I showed you basically how we are improving the safety and convenience of driving today and how we deploy deep learning into production and support all the features of the auto pal today and then I also showed you all the we are doing to develop full self-driving how the neural net is eating through the software stack and how we are putting a vision and AI at the front and center of this effort. So, if you’d like to make your AI expertise count I think there is basically no more impactful or better place to apply some of that expertise then at Tesla today and if you’d like to be a part of what I’ve shown you then come to Tesla dot-com / autopilot ai and you can just directly apply them the page is extremely painless and that just comes directly to us and you can help work with us too you know and make this all work so thank you
Questions
Thank You Andre that was that was awesome so so we have time for a couple of questions while while Ilya is setting up hi so when you do these estimations let’s say of a stop sign and other cars other vehicles in your fleet have driven by it before do you have a way of incorporating the prior from their estimation or you have to reassume eight from scratch yep so we do collect maps we just don’t collect high-definition maps like when a way mow or some plant that is driving through an environment they know that the leaf on that tree is 15.5 three meters away like two centimeter level accuracy we don’t know about the leaf of that tree but we do know that there’s a stop sign somewhere in the vicinity here and so we do build low definition Maps we do map stop signs traffic lights and things like that because it provides a second layer and then also that helps us again like a mission it helps us with all the trigger infrastructure for sourcing examples because we can look for discrepancies between map and vision and that’s a really good signal for us for getting lots of more images of really tricky cases so like I drove by the stop sign yesterday yes I asked tomato does a stop sign yes drive by it today yes thank you so much okay hi under thank you for the great talk I’m very interested in the software 2-0 part and I follow progress I think you mentioned it at scaled Emmaus I wonder what’s your overall vision for this what’s on the main findings this is something that will supplant programming languages will be kind of changed the way that the science is done what they are visual for this and can the community help you know is it something that you know everybody can use to improve rapidly the whole progress with the designs yeah so thank you that’s a very broad question I think what I what I’ve seen so far is just porting functionality from software 1.0 2.0 is not always a good idea it’s good idea sometimes you’re actually it’s a different way of programming but you’re you’re placing yourself in a very indirect control of the final of the final function so sometimes you just want to like write a rule if you’re doing it in a software 2.0 stack everything is so indirect because you’re massaging the data set and you’re going through a training process that takes days the iteration is slower you have to do all of this data engine stuff so anything that’s in the software to pronunce tactic has a cost to it it you’re committing to a lots of data engine costs and any new problem that you find suddenly requires a whole data engine passing curation and so that’s not always a win it’s just sometimes a win and so what we see actually is we kind of like combine software 1.0 and 2.0 so the old older systems as I would describe them in the software on panel stack they don’t always go away you almost think of it as like sedimentary layers where you have the new functionality but the software monpa notice is used for example to keep sort of guarding rails a lot around the software 2.0 part so we almost see them as you do a bit of both and they all they both have pros and cons but I do think that the trend to large extent has been towards the software 2.0 it is a more powerful sort of is a more powerful way of addressing a lot of problems that are very messy and really hard to code and which is a lot of problems in the world but we definitely see that they come with their own pros and cons thank you drea we should move on I really appreciate your time and thanks again [Applause]